[ML] Logistic Regression
Classification
Classification은 정성적(qualitative) 변수, 즉 순서가 없는 집합 $C$에서 값을 가지는 변수를 다루는 문제.
e.g.)
- $\text{eye color} \in {\text{brown, blue, green}}$
- $\text{email} \in {\text{spam, ham}}$
Feature vector $\mathbf{x}$와 qualitative response $\mathbf{y} \in C$가 주어졌을 때, classification의 목표는 $f(\mathbf{x}) \in C$인 함수 $f$를 만드는 것.
그런데 실제로는 단순히 카테고리를 예측하는 것보다 각 카테고리에 속할 확률을 추정하는 게 더 유용한 경우가 많음. 예를 들어 보험금 청구가 사기인지 아닌지를 단순히 yes/no로 답하는 것보다, “사기일 확률이 얼마인가”를 추정하는 게 의사결정에 훨씬 도움이 됨.
Logistic Regression의 등장
Linear Regression의 한계
이진 분류 문제를 생각해보자 (Default). 다음처럼 코딩한다고 가정:
\[\mathbf{y} = \begin{cases} 0 & \text{if No} \\ 1 & \text{if Yes} \end{cases}\]질문: 그냥 linear regression으로 $\mathbf{y}$를 $\mathbf{x}$에 대해 회귀시키고, $\hat{\mathbf{y}} > 0.5$이면 Yes로 분류하면 안 되나?
- 이론적으로 보면 이게 말이 안 되는 건 아님
- 모집단에서 $\mathbb{E}[\mathbf{y} \mid \mathbf{x}] = p(\mathbf{y} = 1 \mid \mathbf{x})$이므로 regression이 될 것 같음
- 실제로 binary outcome의 경우 linear regression이 classifier로서 꽤 잘 동작하며, 나중에 다룰 linear discriminant analysis와도 동치임.
문제점:
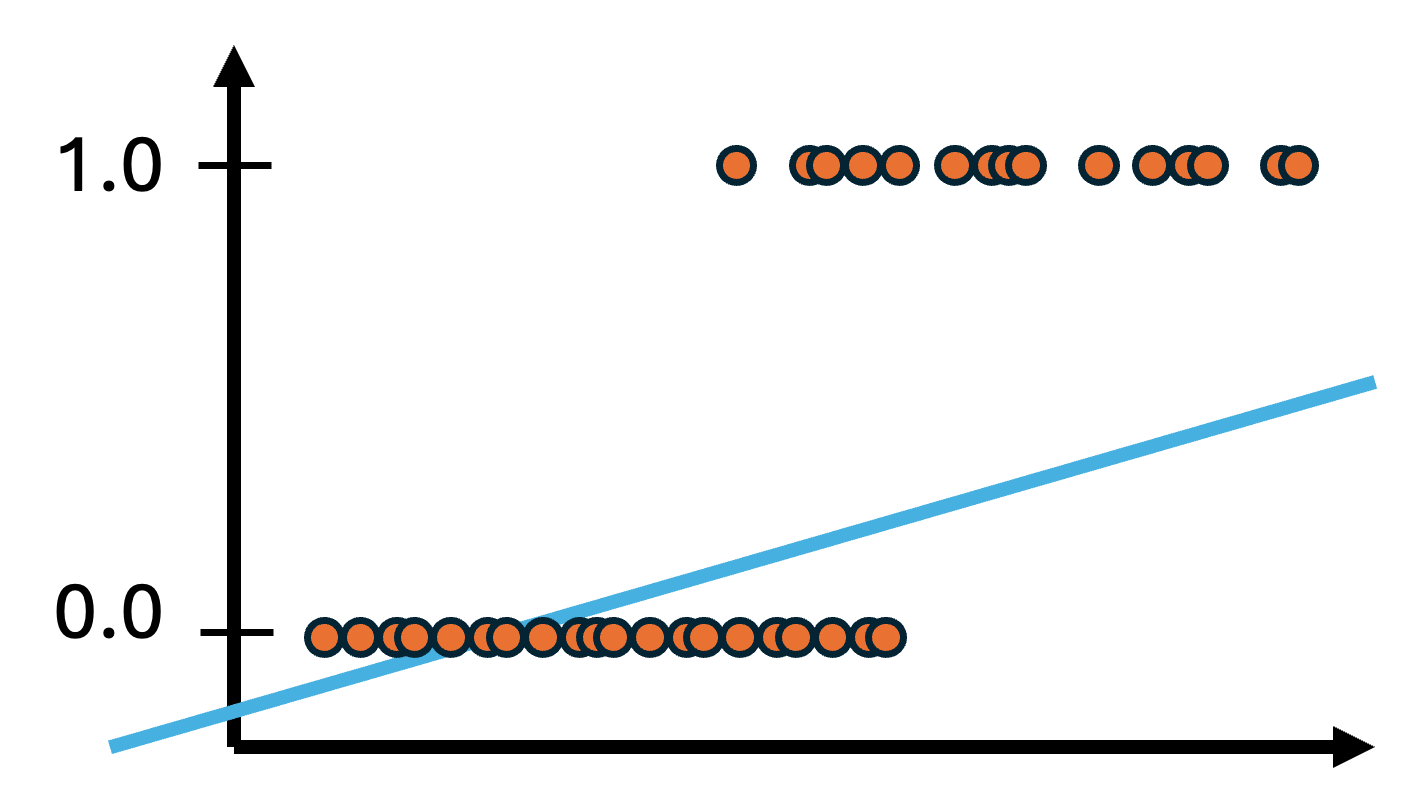
x input에 대한 y의 분포가 분리되어 있을 때, 기울기가 편향되게 설정됨
linear regression은 0보다 작거나 1보다 큰 확률을 출력할 수 있음
- 확률은 $[0, 1]$ 범위에 있어야 하는데, 직선은 무한대로 뻗어나가므로 이를 만족시킬 수가 없음.
Multiclass 문제에선 더 심각함
3개 이상의 클래스가 있는 경우를 생각해보자. 응급실에 환자가 왔을 때 증상으로 분류한다고 하면:
\[Y = \begin{cases} 1 & \text{if stroke} \\ 2 & \text{if drug overdose} \\ 3 & \text{if epileptic seizure} \end{cases}\]이 코딩은 암묵적으로 순서를 가정함
- stroke와 drug overdose 사이의 차이가 drug overdose와 epileptic seizure 사이의 차이와 같다고 가정
- stroke와 epileptic seizure은 차이가 2배 남
- multiclass에서도 linear regression은 부적절
Solution : Logistic Regression
Motivation: 우리가 원하는 함수의 모양
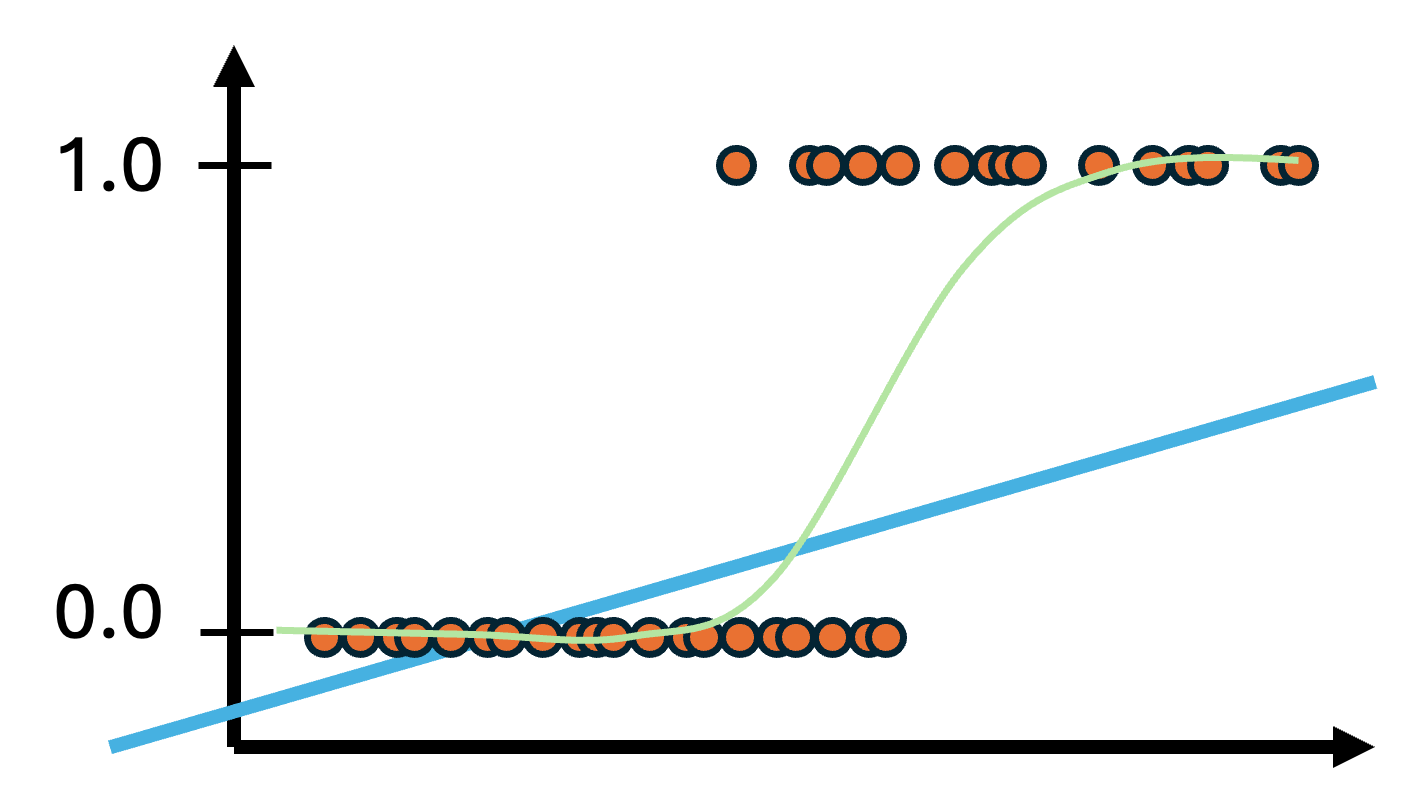 확률을 예측하려면 다음 성질을 가진 함수가 필요함:
확률을 예측하려면 다음 성질을 가진 함수가 필요함:
- 양쪽 끝에서 각각 0과 1로 수렴
- 중간에서는 부드럽게 전환
직선은 절대 이런 nonlinear한 관계를 학습할 수 없음.
그래서 linear function의 출력을 어떻게든 변환해서 $[0, 1]$로 제한하고 싶음.
problem definition
단순화를 위해 binary classification으로 시작:
\[\mathbf{x} \in \mathbb{R}^d, \quad \mathbf{y} \in {-1, +1}\]Positive class “+1”에 속할 확률을 $p$라 하자.
linear regression score $s$를 입력으로 받아 다음과 같이 동작하는 함수를 원함:
- $s$가 크면 $p \to 1$
- $s$가 작으면 (음의 방향으로 크면) $p \to 0$
- $s \approx 0$이면 $p \approx 0.5$
Sigmoid Function
이 모든 요구사항을 만족하는 함수가 바로 sigmoid function임:
\[\sigma(s) = \frac{1}{1 + e^{-s}}\]성질을 보면:
- $s \to \infty$일 때 $\sigma(s) \to 1$
- $s \to -\infty$일 때 $\sigma(s) \to 0$
- $s = 0$일 때 $\sigma(s) = \frac{1}{2}$
즉, linear regression 모델이 nonlinearity를 신경 쓰지 않고도, positive class에 속할 가능성이 높을수록 큰 값을, 낮을수록 작은 값을 출력하도록 학습시키면 됨. 나머지는 sigmoid가 알아서 $[0, 1]$로 매핑해줌.
Logistic Regression
$\mathbf{y} \in {-1, +1}$ 에서
Sigmoid의 출력이 $[0, 1]$ 범위이므로, 아래 모델 출력을 class 1에 속할 확률로 해석할 수 있음:
\[p(\mathbf{y} = 1 \mid \mathbf{x}) = \frac{1}{1 + e^{-\beta^\top \mathbf{x}}}\]그렇다면 negative class $(-1)$의 확률은?
- Class가 2개뿐이므로 $p(\mathbf{y} = 1 \mid \mathbf{x}) + p(\mathbf{y} = -1 \mid \mathbf{x}) = 1$을 만족해야 함.
이렇게 conditional distribution $p(\mathbf{y} \mid \mathbf{x})$를 직접 모델링하는 방식을 logistic regression이라 함.
- 이름엔 “regression”이 들어가지만, target variable $\mathbf{y}$가 discrete이므로 사실은 classifier임.
Log Odds
Default 데이터에서 학습한 결과로 $\hat{\beta}_1 = 0.0055$가 나왔다고 하자
- 이는 balance가 증가하면 default 확률이 증가한다는 뜻
큰 그림에서는 linear regression의 해석과 비슷함.
- 정확하게 말하면, balance가 1 단위 증가할 때 default의 log odds가 0.0055만큼 증가함.
식을 $1 + e^{-\beta^\top \mathbf{x}} \rightarrow \beta_0 + \beta_1 X$ 로 두고 아래와 같이 재구성할 수 있음.
\[\text{log odds} = \log\left(\frac{p(X; \boldsymbol{\beta})}{1 - p(X; \boldsymbol{\beta})}\right) = \beta_0 + \beta_1 X\]- Positive class 확률이 올라가면 값이 커짐
- negative class 확률이 올라가면 값이 작아짐
- 이 관계를 선형적으로 모델링하겠다
- $X$ 값이 한 unit 올라갔을 때 log odds가 $\beta_1$만큼 선형적으로 비례한다
- 즉 logistic regression은 log odds에 대해 선형 모델을 fit시키는 것
예측 예시
학생의 공부 시간(시간 단위)으로 시험 합격 여부를 예측하는 logistic regression을 학습시켰다고 하자.
결과:
\(\log\left(\frac{p}{1-p}\right) = -3 + 1 \cdot x\)
$\hat{\beta}_0 = -3$, $\hat{\beta}_1 = 1$.
Odds
확률과 odds(승산)는 다름:
| 확률 $p$ | Odds $\frac{p}{1-p}$ | 해석 |
|---|---|---|
| 0.5 | 1 (= 1:1) | 합격할 확률 = 불합격할 확률 |
| 0.75 | 3 (= 3:1) | 합격할 가능성이 불합격할 가능성의 3배 |
| 0.9 | 9 (= 9:1) | 합격 가능성이 9배 |
| 0.99 | 99 | 합격 가능성이 99배 |
도박판에서 “3 대 1 배당”이라고 할 때 그 odds임. 확률을 비율로 본 것임.
공부 시간별 계산
$x = 2$시간일 때: \(\log\left(\frac{p}{1-p}\right) = -3 + 1 \cdot 2 = -1\) \(\frac{p}{1-p} = e^{-1} \approx 0.37 \quad\Rightarrow\quad p \approx 0.27\)
$x = 3$시간일 때: \(\log\left(\frac{p}{1-p}\right) = -3 + 1 \cdot 3 = 0\) \(\frac{p}{1-p} = e^{0} = 1 \quad\Rightarrow\quad p = 0.5\)
$x = 4$시간일 때: \(\log\left(\frac{p}{1-p}\right) = -3 + 1 \cdot 4 = 1\) \(\frac{p}{1-p} = e^{1} \approx 2.72 \quad\Rightarrow\quad p \approx 0.73\)
$x = 5$시간일 때: \(\log\left(\frac{p}{1-p}\right) = -3 + 1 \cdot 5 = 2\) \(\frac{p}{1-p} = e^{2} \approx 7.39 \quad\Rightarrow\quad p \approx 0.88\)
$\hat \beta_1$
공부 시간이 1시간 늘어날 때마다:
| 변화 | 값 |
|---|---|
| log-odds 변화 | $+1$ (선형으로 증가) |
| odds 배율 | $e^1 \approx 2.72$배 |
| 확률 $p$ | 0.27 → 0.5 → 0.73 → 0.88 (비선형) |
핵심은:
- Log-odds는 깔끔하게 선형으로 증가 ($+1, +1, +1, \ldots$)
- Odds는 매번 $e^{\hat{\beta}_1}$배씩 곱해짐 (약 2.72배씩)
- 확률 $p$는 sigmoid 곡선을 따라 비선형으로 움직임
MLE: Logistic Regression 학습하기
Likelihood 정의
$\beta$를 학습하기 위해 Maximum Likelihood Estimation을 사용.
Conditional distribution $p(\mathbf{y} \mid \mathbf{x})$를 최대화하는 $\beta$를 찾는 게 목표:
\[\mathcal{L}(\beta) = \prod_{i: \mathbf{y}_i = 1} p(\mathbf{y}_i = 1 \mid \mathbf{x}_i) \prod_{j: \mathbf{y}_j = -1} p(\mathbf{y}_j = -1 \mid \mathbf{x}_j)\]- 이 likelihood는 관측된 데이터에서 positive(+1)와 negative(-1)가 나올 확률을 의미함
- 이 값을 최대로 만드는 $\beta$를 선택
Log-Likelihood로 정리
곱을 합으로 바꾸기 위해 log를 씌움:
\[\log \mathcal{L}(\beta) = \sum_{i: \mathbf{y}_i = 1} \log p(\mathbf{y}_i = 1 \mid \mathbf{x}_i) + \sum_{j: \mathbf{y}_j = -1} \log p(\mathbf{y}_j = -1 \mid \mathbf{x}_j)\]각각의 형태를 대입:
- $p(\mathbf{y}_i = 1 \mid \mathbf{x}_i) = \dfrac{1}{1 + e^{-\beta^\top \mathbf{x}_i}}$
- $p(\mathbf{y}_j = -1 \mid \mathbf{x}_j) = \dfrac{1}{1 + e^{\beta^\top \mathbf{x}_j}}$
여기서 $\mathbf{y} \in {-1, +1}$이라는 점을 활용하면 두 식을 하나로 묶을 수 있음:
\[\log \mathcal{L}(\beta) = \sum_{i=1}^{n} \log \frac{1}{1 + e^{-\mathbf{y}_i \beta^\top \mathbf{x}_i}}\]- $\mathbf{y}_i$가 부호를 뒤집어주는 역할을 해서 positive와 negative 케이스를 동시에 처리함
Closed-Form Solution이 없음
이제 $\beta$에 대해 미분해서 0으로 놓으면:
\[\log \mathcal{L}(\beta) = -\sum_{i=1}^n \log(1 + e^{-\mathbf{y}_i \beta^\top \mathbf{x}_i})\] \[\frac{\partial \log \mathcal{L}(\beta)}{\partial \beta} = 0 \Rightarrow \sum_{i=1}^{n} \frac{\mathbf{x}_i \mathbf{y}_i e^{-\mathbf{y}_i \beta^\top \mathbf{x}_i}}{1 + e^{-\mathbf{y}_i \beta^\top \mathbf{x}*i}} = 0 \Rightarrow \sum_{i=1}^{n} \frac{\mathbf{x}_i \mathbf{y}_i}{1 + e^{\mathbf{y}_i \beta^\top \mathbf{x}_i}} = 0\]문제:
이 식은 closed-form solution이 존재하지 않음.
- Linear regression처럼 깔끔하게 $\hat{\beta} = (X^\top X)^{-1} X^\top y$ 같은 normal equation이 나오지 않음
- 다른 최적화 기법이 필요함.
Optimization: Gradient Descent
Supervised Learning Framework
ML은 data-driven 접근법.
일반적인 흐름:
- Step 1: 모델의 형태를 설계 (예: $p(\mathbf{y} \mid \mathbf{x}) = \frac{1}{1 + e^{-\mathbf{y}\beta^\top \mathbf{x}}}$)
- Step 2: 목표 정의 ($\mathbf{y} \approx f(\mathbf{x})$가 최대한 잘 되도록)
- Step 3: Training data ${(\mathbf{x}_i, \mathbf{y}_i): i = 1, \ldots, n}$로부터 최적의 $\beta$ 찾기 ← 이 부분이 지금 안 됨
- Step 4: Unseen $\mathbf{x}$에 대해 $p(\hat{\mathbf{y}} \mid \mathbf{x})$ 계산
Logistic regression에서 Step 3가 closed-form solution이 없으므로, 다른 방법이 필요함.
Optimization이란?
Wikipedia: Mathematical optimization은 어떤 기준(criterion)에 따라 주어진 대안들의 집합에서 최선의 원소를 선택하는 것임.
이걸 ML 맥락으로 옮기면:
- “어떤 기준” → loss function $\mathcal{L}(\hat{y}, y)$
- “최선의 원소” → 최적의 parameter $\beta$
- “대안들의 집합” → parameter space
가장 단순하게 떠올릴 수 있는 방법들:
- Exhaustive search (모든 경우 다 해보기)
- Random search (랜덤하게 던지고 best 선택)
- Visualization (그려보고 눈으로 찾기)
Greedy search (변수 하나씩 차례로 푸는 것)
- 고차원에서 이런 방법은 전혀 작동하지 않음
Gradient Descent
우리에겐 최소화하고 싶은 cost function (loss function) $\mathcal{L}(\beta)$가 있음.
아이디어:
- 현재 $\beta$에서 $\mathcal{L}(\beta)$의 gradient 계산
- Gradient의 반대 방향으로 작은 한 걸음 이동
- 반복
Gradient(미분)는 어떤 점에서 함수의 best linear approximation임.
즉 함수가 가장 빠르게 증가하는 방향을 알려주므로, 그 반대 방향으로 가면 가장 빠르게 감소함.
Update 식
Vector notation:
\[\beta^{\text{new}} = \beta^{\text{old}} - \alpha \nabla_\beta \mathcal{L}(\beta)\]각 parameter에 대해 적으면:
\[\beta_i^{\text{new}} = \beta_i^{\text{old}} - \alpha \frac{\partial}{\partial \beta_i^{\text{old}}} \mathcal{L}(\beta)\]- 여기서 $\alpha$는 learning rate (보폭의 크기).
Pseudocode:
1
2
3
4
5
beta = rand(vector)
while true:
beta_grad = evaluate_gradient(L, data, beta)
beta = beta - alpha * beta_grad
if (norm(beta_grad) <= threshold) break
- 직관적으로 slope가 음수면 오른쪽($\beta$ 증가)으로, 양수면 왼쪽($\beta$ 감소)으로 가야 함
- $-\alpha \cdot \text{slope}$가 정확히 이 동작을 함.
Gradient Descent의 잠재적 문제들
- Convex하지 않을 수 있음
- Local optima나 saddle point가 많을 수 있음.
- 거기서도 gradient가 0이지만 global minimum은 아님.
- 미분 가능해야 함
- 어떤 loss function(예: 0/1 loss)은 항상 미분 가능하지 않음
- 이 경우 부드러운 surrogate function을 대신 사용함.
- 수렴이 느릴 수 있음
- 모든 data sample에서 gradient를 계산해서 평균을 내야 하므로, 데이터가 크면 한 step에 시간이 오래 걸림.
Stochastic Gradient Descent (SGD)
마지막 문제를 해결하기 위해, 전체 데이터가 아니라 무작위로 샘플링한 부분집합에서만 gradient를 계산하는 방법:
- 가장 극단적 케이스: 매 sample마다 update (true SGD)
- 일반적: minibatch 단위로 update.
- 보통 32, 64, 128, 256, …, 8192 사이의 크기 사용
- 최적 배치 크기는 문제, 데이터, 하드웨어(특히 memory)에 따라 다름
Minibatch가 작을 때는 크기를 두 배로 늘리면 gradient 추정이 훨씬 안정적으로 변함.
하지만 어느 정도 이상 커지면 추가 안정성은 미미해지고 비용만 두 배가 됨 → diminishing returns.
실제 학습 곡선에 대해서
- 왜 noisy한 곡선이 나오는가?
- SGD에서 minibatch마다 gradient가 다르므로 update가 흔들림.
- 전체 데이터의 평균 방향이 아니라 sample 기반 추정이라서 그럼.
- 언제 학습을 멈춰야 하는가?
- Loss가 더 이상 의미 있게 줄지 않거나, validation loss가 오르기 시작하는 시점 (early stopping)
정리된 Supervised Learning Framework
이제 Step 3를 좀 더 세분화할 수 있음:
- Step 1: 모델 형태 설계
- Step 2: 목표 정의
- Step 3 : 최적의 $\beta$ 찾기
- Step 3-1: Training example $\mathbf{x}_i$를 모델에 넣어 $\hat{\mathbf{y}}_i$ 추정
- Step 3-2: $\hat{\mathbf{y}}_i$를 실제 label $\mathbf{y}_i$와 비교 → loss function으로 평가 (logistic regression에선 log-loss)
- Step 3-3: 이 loss로 $\beta$ update (closed-form이 없으면 SGD)
- 대부분의 training data에서 $\hat{\mathbf{y}}_i \approx \mathbf{y}_i$가 될 때까지 반복
- Step 4: Unseen $\mathbf{x}$에 대해 $p(\hat{\mathbf{y}} \mid \mathbf{x})$ 계산
Logistic Regression의 확장
변수가 2개 이상일 때 ($p > 1$)
Linear regression처럼, log-odds에 대한 linear model을 그냥 다변수로 확장하면 됨:
\[\log\left(\frac{p(X; \boldsymbol{\beta})}{1 - p(X; \boldsymbol{\beta})}\right) = \beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p\] \[p(X; \boldsymbol{\beta}) = \frac{e^{\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p}}{1 + e^{\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p}}\]- $p+1$개의 parameter를 가짐 (intercept 포함).
핵심은 logistic regression의 형태가 변수 수와 무관하게 그대로 유지됨:
\[p(\mathbf{y} \mid \mathbf{x}) = \frac{1}{1 + e^{-\mathbf{y}\beta^\top \mathbf{x}}}\]- 여기서 $\mathbf{x}$와 $\beta$는 $(p+1)$-차원 벡터.
클래스가 3개 이상일 때 ($K > 2$)
2-class logistic regression은 두 가지 형태로 표현 가능했음:
- Log-odds가 $\mathbf{x}$에 대해 선형: \(\log\left(\frac{p(\mathbf{y} \mid \mathbf{x})}{1 - p(\mathbf{y} \mid \mathbf{x})}\right) = \beta^\top \mathbf{x}\)
- 각 class의 conditional probability가 sigmoid 형태: \(p(\mathbf{y} = 1 \mid \mathbf{x}) = \frac{1}{1 + e^{-\beta^\top \mathbf{x}}}, \quad p(\mathbf{y} = -1 \mid \mathbf{x}) = \frac{1}{1 + e^{\beta^\top \mathbf{x}}}\)
그런데 3 클래스로 가면 이 두 형태를 그대로 쓰기 어려움.
- $p(\mathbf{y}=0|\mathbf{x})$, $p(\mathbf{y}=1|\mathbf{x})$, $p(\mathbf{y}=2|\mathbf{x})$를 동시에 다루는 방식이 자연스럽지 않음.
세 번째 형태 유도
해결책: $p(\mathbf{y}=1|\mathbf{x})$와 $p(\mathbf{y}=-1|\mathbf{x})$에 공통 분모 형태를 만듦.
$p(\mathbf{y}=1|\mathbf{x})$의 분자/분모에 $e^{\frac{\beta^\top}{2}\mathbf{x}}$를 곱하면:
\[p(\mathbf{y} = 1 \mid \mathbf{x}) = \frac{1}{1 + e^{-\beta^\top \mathbf{x}}} = \frac{e^{\frac{\beta^\top}{2}\mathbf{x}}}{e^{\frac{\beta^\top}{2}\mathbf{x}} + e^{-\frac{\beta^\top}{2}\mathbf{x}}}\]$p(\mathbf{y}=-1|\mathbf{x})$의 분자/분모에 $e^{-\frac{\beta^\top}{2}\mathbf{x}}$를 곱하면:
\[p(\mathbf{y} = -1 \mid \mathbf{x}) = \frac{1}{1 + e^{\beta^\top \mathbf{x}}} = \frac{e^{-\frac{\beta^\top}{2}\mathbf{x}}}{e^{\frac{\beta^\top}{2}\mathbf{x}} + e^{-\frac{\beta^\top}{2}\mathbf{x}}}\]이제 $\beta/2$를 $\beta_1’$, $-\beta/2$를 $\beta_{-1}’$로 renaming:
\[p(\mathbf{y} = 1 \mid \mathbf{x}) = \frac{e^{\beta_1'^\top \mathbf{x}}}{e^{\beta_1'^\top \mathbf{x}} + e^{\beta_{-1}'^\top \mathbf{x}}}, \quad p(\mathbf{y} = -1 \mid \mathbf{x}) = \frac{e^{\beta_{-1}'^\top \mathbf{x}}}{e^{\beta_1'^\top \mathbf{x}} + e^{\beta_{-1}'^\top \mathbf{x}}}\]- 분자: 해당 클래스의 linear score를 exponential 취한 값
- 분모: 모든 클래스의 score의 exponential의 합
Softmax Function
이 형태는 자연스럽게 $K$개 클래스로 확장됨.
$i$번째 클래스의 score를 $s_i = \boldsymbol{\beta}_i^\top \mathbf{x}$라 하면:
\[p(\mathbf{y} = i \mid \mathbf{x}) = \frac{e^{s_i}}{e^{s_1} + e^{s_2} + \cdots + e^{s_K}} = \frac{e^{s_i}}{\sum_{j=1}^{K} e^{s_j}}\]- 이게 Softmax Function
Softmax가 확률 분포의 조건을 만족하는가?
- $0 \le p(\mathbf{y} = i \mid \mathbf{x}) \le 1$?
- $e^{s_i} \ge 0$이고 분모 $\ge$ 분자이므로 만족함.
- $\sum_{i=1}^{K} p(\mathbf{y} = i \mid \mathbf{x}) = 1$?
- 분자들의 합이 정확히 분모이므로 만족함.
- 깔끔하게 확률 분포의 조건을 만족함. Softmax는 이후 neural network의 multi-class classification에서도 표준적으로 사용되는 함수임.
Logistic Regression 요약
전체 학습 과정을 한 줄로 정리하면, conditional distribution $p(\mathbf{y} \mid \mathbf{x})$를 최대화하는 $\beta$를 찾는 것임:
\[\begin{aligned} \hat{\beta} &= \underset{\beta}{\operatorname{argmax}} \sum_{i=1}^n \log p(\mathbf{y}_i \mid \mathbf{x}_i) \\ &= \underset{\beta}{\operatorname{argmax}} \sum_{i=1}^n \log \frac{1}{1 + e^{-\mathbf{y}_i \beta^\top \mathbf{x}_i}} \\ &= \underset{\beta}{\operatorname{argmin}} \sum_{i=1}^n \log(1 + e^{-\mathbf{y}_i \beta^\top \mathbf{x}_i}) \end{aligned}\]- 마지막 줄(최소화하는 형태의 목적함수)이 Log-Loss (또는 logistic loss, cross-entropy loss의 binary 버전)
- likelihood maximize = loss function minimize
결국 logistic regression은 linear regression을 분모에 지수로 넣어서 ($e^{-\beta^\top \mathbf{x}}$), 시그모이드로 확률 모델로 사용하는 것
- $p(y|x)$를 모델링한다고 가정하고, MLE로 학습
- 출력이 그냥 점수가 아니라 calibrated probability ($\because$ 학습할 때 likelihood 최대화. 모델의 출력이 진짜 확률 분포이고, 그 분포 하에서 관측된 데이터가 가장 그럴듯하게 만드는 $\beta$를 찾자.)
- Log odds 관점에서도, logistic regression은 확률에 sigmoid를 씌운 게 아니라, log-odds를 $\bf x$의 선형 함수로 모델링한 것
마무리: ML 학습의 일반적 구조
Logistic regression을 통해 ML의 일반적인 학습 구조가 명확해짐:
- 모델 ($p(\mathbf{y} \mid \mathbf{x}) = \frac{1}{1 + e^{-\mathbf{y}\beta^\top \mathbf{x}}}$): 데이터를 어떻게 표현할지의 가설
- Loss function ($\sum_{i=1}^n \log(1 + e^{-\mathbf{y}_i \beta^\top \mathbf{x}_i})$): 예측이 얼마나 틀렸는지 측정
- Optimization (gradient descent / SGD): closed-form이 없을 때 loss를 줄이는 방향으로 parameter 업데이트
이 세 가지 요소(모델 / 손실 / 최적화)는 이후 neural network, deep learning까지 동일하게 적용되는 framework임.
Logistic regression은 그중에서도 가장 단순한 형태이면서, sigmoid → softmax, log-loss → cross-entropy로 자연스럽게 일반화되는 좋은 출발점임.