[ML] Ensemble Methods & Boosting
Bootstrapping
머신러닝에서는 데이터 양이 부족한 상황을 자주 겪음.
가능하면 더 많은 샘플을 모으는 게 좋지만, 항상 가능하지도 않고 비용도 큼.
그래서 주어진 데이터로 최선을 다해보자는 발상이 등장함.
부트스트래핑의 어원 : 도움 받지 말고 스스로 상황을 개선시켜 보자
실제 분포(true distribution)에서 추가 데이터를 샘플링하는 건 일반적으로 불가능함.
분포 자체가 우리가 추정하려는 대상이기 때문.
그래서 모집단에서 독립적으로 데이터를 반복 추출하는 대신, 원본 데이터셋에서 복원 추출(with replacement)을 반복해서 서로 다른 데이터셋을 얻음.
: Bootstrapping
- 하나의 데이터셋을 재추출해서 여러 개의 시뮬레이션된 샘플을 만들어내는 통계 도구
- 각 “부트스트랩 데이터셋”은 원본과 같은 크기로 복원 추출됨
- 따라서 어떤 관측치는 여러 번 등장할 수도 있고, 어떤 관측치는 한 번도 등장하지 않을 수도 있음
- 불확실성을 정량화하는 데 사용할 수 있음
- e.g. 어떤 계수의 표준오차나 신뢰구간을 추정할 수 있음
예시
원본 데이터 $Z = {(4.3, 2.4), (2.1, 1.1), (5.3, 2.8)}$가 있을 때, 복원 추출로 $Z^{*1}, Z^{*2}, \ldots, Z^{*B}$를 만들고, 각각에서 관심 모수 $\alpha$를 추정해서 $\hat{\alpha}^{*1}, \hat{\alpha}^{*2}, \ldots, \hat{\alpha}^{*B}$를 얻음.
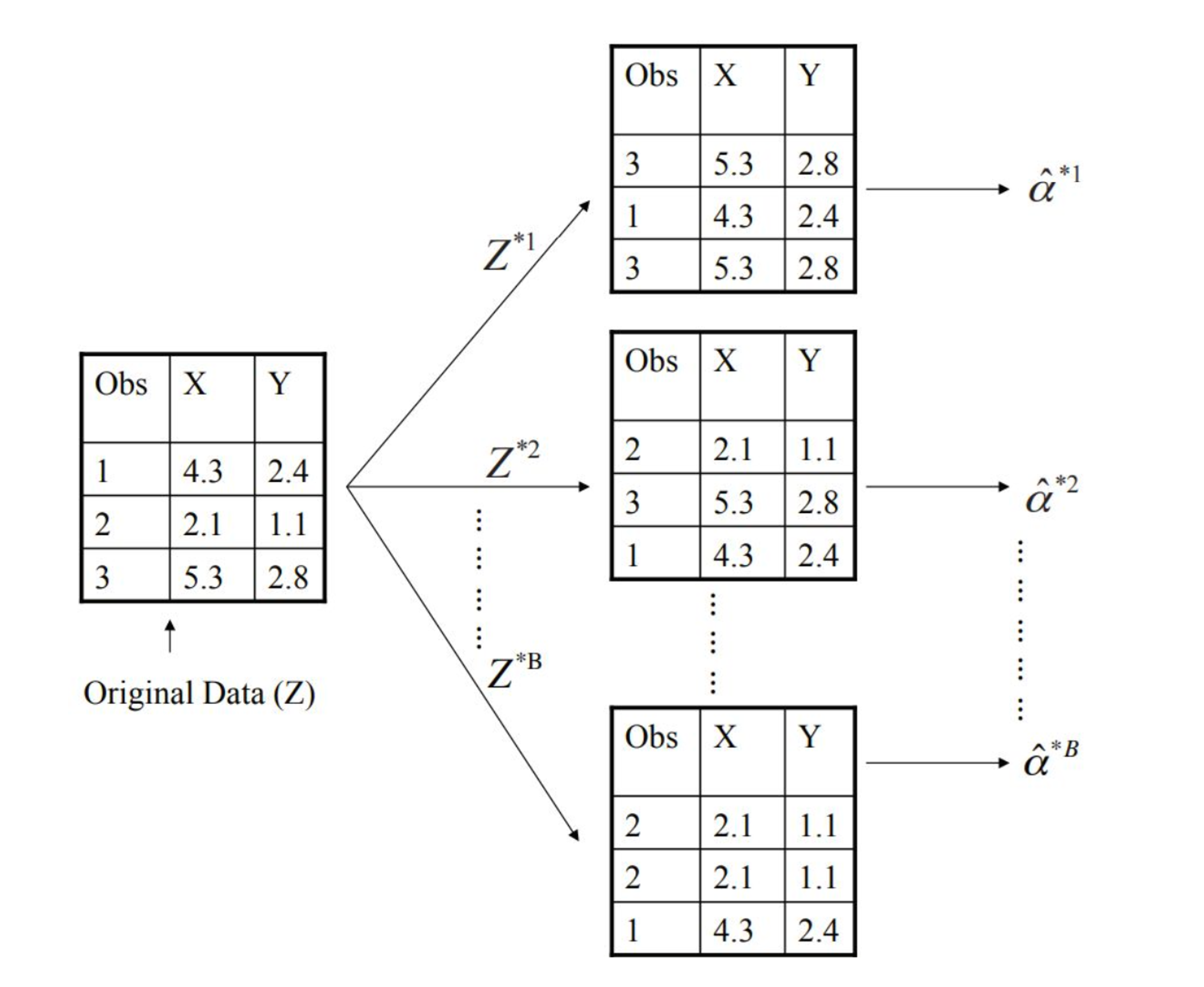
이로부터 $\hat{\alpha}$의 표준오차 추정값을 계산:
\[\mathrm{SE}*B(\hat{\alpha}) = \sqrt{\frac{1}{B-1} \sum_{r=1}^{B} \left(\hat{\alpha}^{*r} - \bar{\hat{\alpha}}^{*}\right)^2}\]부트스트래핑의 한계
부트스트래핑의 핵심 가정은 샘플들이 i.i.d. (독립항등분포)라는 것임.
이 가정이 깨지는 대표적인 예가 시계열 데이터.
시계열은 단순 복원 추출이 불가능하니, 대신 연속된 관측치의 블록(block)을 만들어 그 블록을 복원 추출함.
그리고 추출된 블록들을 이어붙여서 부트스트랩 데이터셋을 만듦.
- e.g. 세션 기반 추천(session-based recommendation)
Bootstrapping vs. cross validation
Q. 부트스트랩으로 prediction error를 추정할 수 있을까? $k$개의 부트스트랩을 만들고 $k-1$개로 학습, 나머지 1개로 검증하면 $k$-fold CV처럼 되지 않을까?
A. 안 됨.
이유:
$k$-fold cross-validation에서는 각 validation fold가 training fold와 겹치지 않음. 이 점이 성공의 핵심.
반면 각 부트스트랩은 복원 추출 때문에 서로 상당히 많이 겹침.
사실 원본 데이터 포인트 중 약 2/3가 각 부트스트랩 샘플에 나타남.
왜 2/3인가?
- $n$개 샘플에서 $n$번 복원 추출할 때, 특정 샘플이 한 번도 안 뽑힐 확률은 $(1 - 1/n)^n$
- $n \to \infty$일 때:
- \[\lim_{n \to \infty} \left(1 - \frac{1}{n}\right)^n = e^{-1} \approx \frac{1}{3}\]
- 따라서 약 $1 - 1/3 = 2/3$가 한 번 이상 등장함.
- 이런 큰 중첩 때문에 부트스트랩으로 prediction error를 추정하면 실제보다 심각하게 과소추정하게 됨.
Bagging (Bootstrap Aggregation)
Bagging은 다음과 같이 동작함:
- 단일 학습 데이터셋에서 $B$개의 부트스트랩 데이터셋을 만듦
- $b$번째 부트스트랩 학습 데이터로 모델을 학습해서 $\hat{f}^{*b}(x)$를 얻음
- 모든 예측을 평균냄:
- \[\hat{f}_{\mathrm{bag}}(x) = \frac{1}{B} \sum_{b=1}^{B} \hat{f}^{*b}(x)\]
Bagging은 예측값을 평균내는 것이지 중간 변수를 평균내는 게 아니므로, 어떤 분류/회귀 모델에도 일반적으로 적용 가능함.
- 분류 문제에서는 평균 대신 다수결(majority vote)을 씀.
왜 작동하는가
Bagging은 일종의 집단지성(wisdom of crowd).
- 각 모델의 bias는 동일하지만 variance가 줄어들기 때문에 전체 MSE가 작아짐.
- 독립적인 관측치 $Z_1, \ldots, Z_n$이 각각 분산 $\sigma^2$을 가지면, 평균 $\bar{Z}$의 분산은 $\sigma^2/n$.
- 즉 관측치들을 평균내면 분산이 줄어듦.
Bagging은 bias를 늘리지 않고 variance를 줄이는 기법.
- $n$개 모델을 같은 크기 데이터셋으로 학습시켜야 하는 cost가 있음
Bagging의 이론적 분석
Notation: $y_b(\mathbf{x}) = h(\mathbf{x}) + \epsilon_b(\mathbf{x})$
- $y_b(\mathbf{x})$: $b$번째 모델의 추정값
- $h(\mathbf{x})$: 실제값
- $\epsilon_b(\mathbf{x})$: $b$번째 모델의 오차
단일 모델의 expected error:
\[E_{\text{single}} = \mathbb{E}_{\mathbf{x}} \left[(y_b(\mathbf{x}) - h(\mathbf{x}))^2\right] = \mathbb{E}_{\mathbf{x}}\left[\epsilon_b(\mathbf{x})^2\right]\]$B$개 모델 평균:
\[\frac{1}{B} \sum_{b=1}^{B} \mathbb{E}_{\mathbf{x}}\left[\epsilon_b(\mathbf{x})^2\right]\]combined model의 expected error:
\[E_{\text{comb}} = \mathbb{E}_{\mathbf{x}}\left[(y(\mathbf{x}) - h(\mathbf{x}))^2\right] = \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B} \sum_{b=1}^{B} y_b(\mathbf{x}) - h(\mathbf{x})\right)^2\right]\]Theorem 1. 결합 모델의 expected error는 단일 모델보다 크지 않음
증명:
\[E_{\text{single}} = \frac{1}{B} \sum_{b=1}^{B} \mathbb{E}_{\mathbf{x}}\left[\epsilon_b(\mathbf{x})^2\right] = \mathbb{E}_{\mathbf{x}}\left[\frac{1}{B} \sum_{b=1}^{B} \epsilon_b(\mathbf{x})^2\right]\]여기서 Jensen’s inequality (볼록함수 $f$와 확률변수 $X$에 대해 $\mathbb{E}f(X) \geq f(\mathbb{E}X)$) 적용.
- 볼록함수 위의 두 점을 잇는 직선(현, chord)은 항상 곡선보다 위에 있다
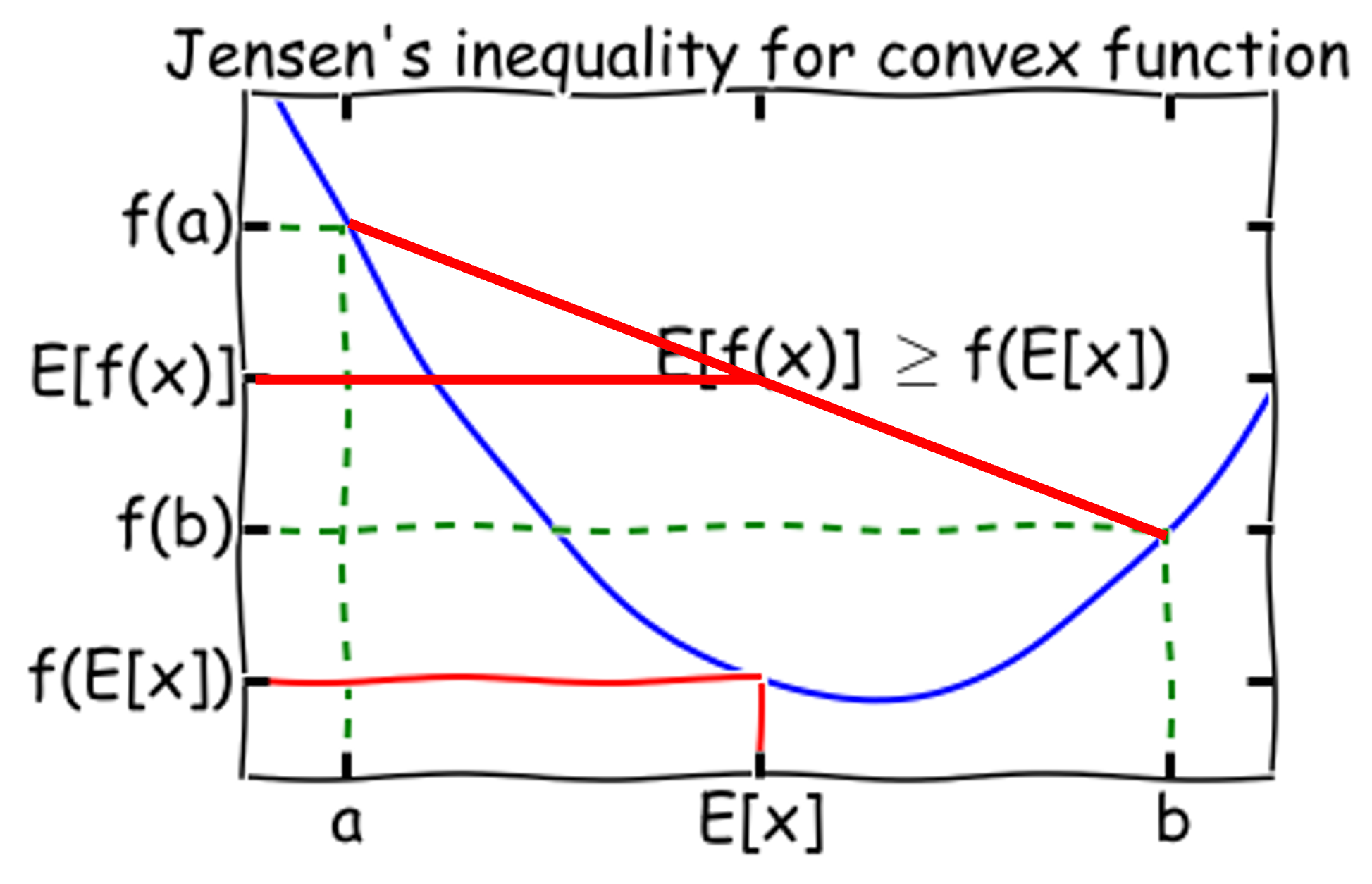
$f(x) = x^2$은 볼록함수이므로:
\[\mathbb{E}_{\mathbf{x}}\left[\frac{1}{B} \sum_{b=1}^{B} \epsilon_b(\mathbf{x})^2\right] \geq \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B} \sum_{b=1}^{B} \epsilon_b(\mathbf{x})\right)^2\right]\] \[= \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B} \sum_{b=1}^{B}(y_b(\mathbf{x}) - h(\mathbf{x}))\right)^2\right]\] \[= \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B} \sum_{b=1}^{B} y_b(\mathbf{x}) - \frac{1}{B}\sum_{b=1}^{B}h(\mathbf{x})\right)^2\right] = \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B} \sum_{b=1}^{B} y_b(\mathbf{x}) - \frac{1}{B}Bh(\mathbf{x})\right)^2\right]\] \[= \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B} \sum_{b=1}^{B} y_b(\mathbf{x}) - h(\mathbf{x})\right)^2\right] = E_{\text{comb}}\]따라서 $E_{\text{single}} \geq E_{\text{comb}}$.
모델을 합쳐서 잃을 건 없음
Theorem 2. 결합 모델의 expected error는 단일 모델의 $1/B$까지 작아질 수 있음
증명:
\[E_{\text{comb}} = \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B} \sum_{b=1}^{B} y_b(\mathbf{x}) - h(\mathbf{x})\right)^2\right] = \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B}(y_1(\mathbf{x}) + \ldots + y_B(\mathbf{x})) - h(\mathbf{x})\right)^2\right]\]$h(\mathbf{x})$를 $B$개로 나눠서 각 항에 분배:
\[= \mathbb{E}_{\mathbf{x}}\left[\left(\frac{1}{B}(y_1(\mathbf{x}) - h(\mathbf{x})) + \ldots + \frac{1}{B}(y_B(\mathbf{x}) - h(\mathbf{x}))\right)^2\right]\]다항식 제곱을 전개 — 제곱항과 교차항이 나옴:
\[= \mathbb{E}_{\mathbf{x}}\left[\frac{1}{B^2}(y_1(\mathbf{x}) - h(\mathbf{x}))^2 + \ldots + \frac{1}{B^2}(y_B(\mathbf{x}) - h(\mathbf{x}))^2 + \frac{2}{B^2}\sum_{\ell \neq k}(y_\ell(\mathbf{x}) - h(\mathbf{x}))(y_k(\mathbf{x}) - h(\mathbf{x}))\right]\]$y_b(\mathbf{x}) - h(\mathbf{x}) = \epsilon_b(\mathbf{x})$이므로:
\[= \mathbb{E}_{\mathbf{x}}\left[\frac{1}{B^2}\epsilon_1(\mathbf{x})^2 + \ldots + \frac{1}{B^2}\epsilon_B(\mathbf{x})^2 + \frac{2}{B^2}\sum_{\ell \neq k}\epsilon_\ell(\mathbf{x})\epsilon_k(\mathbf{x})\right]\] \[= \mathbb{E}_{\mathbf{x}}\left[\frac{1}{B^2}\sum_{b=1}^{B}\epsilon_b(\mathbf{x})^2 + \frac{2}{B^2}\sum_{\ell \neq k}\epsilon_\ell(\mathbf{x})\epsilon_k(\mathbf{x})\right]\]기댓값 선형성으로 분리:
\[= \frac{1}{B^2}\sum_{b=1}^{B}\mathbb{E}*{\mathbf{x}}[\epsilon_b(\mathbf{x})^2] + \frac{2}{B^2}\mathbb{E}*{\mathbf{x}}\left[\sum_{\ell \neq k}\epsilon_\ell(\mathbf{x})\epsilon_k(\mathbf{x})\right]\] \[= \frac{1}{B}\underbrace{\left(\frac{1}{B}\sum_{b=1}^{B}\mathbb{E}_{\mathbf{x}}[\epsilon_b(\mathbf{x})^2]\right)}_{= E_{\text{single}}} + \underbrace{\frac{2}{B^2}\mathbb{E}_{\mathbf{x}}\left[\sum_{\ell \neq k}\epsilon_\ell(\mathbf{x})\epsilon_k(\mathbf{x})\right]}_{\text{공분산 항}}\]이제 두 극단을 보면:
- 모든 $B$개 모델이 완전히 독립이면, 공분산 항이 0이 됨.
- 따라서 $E_{\text{comb}} = \frac{1}{B} E_{\text{single}}$
반대 극단으로 모든 $B$개 모델이 동일하면 $E_{\text{comb}} = E_{\text{single}}$
- 따라서 $E_{\text{comb}}$는 $B$개 모델 사이의 독립성 정도에 비례해서 작아짐.
결론
best case : error가 $1/B$까지 줄어들 수 있다
worst case : error 값 똑같다
모델을 합쳐서 손해볼 게 없다
Bagging with Decision Trees
Bagged Trees
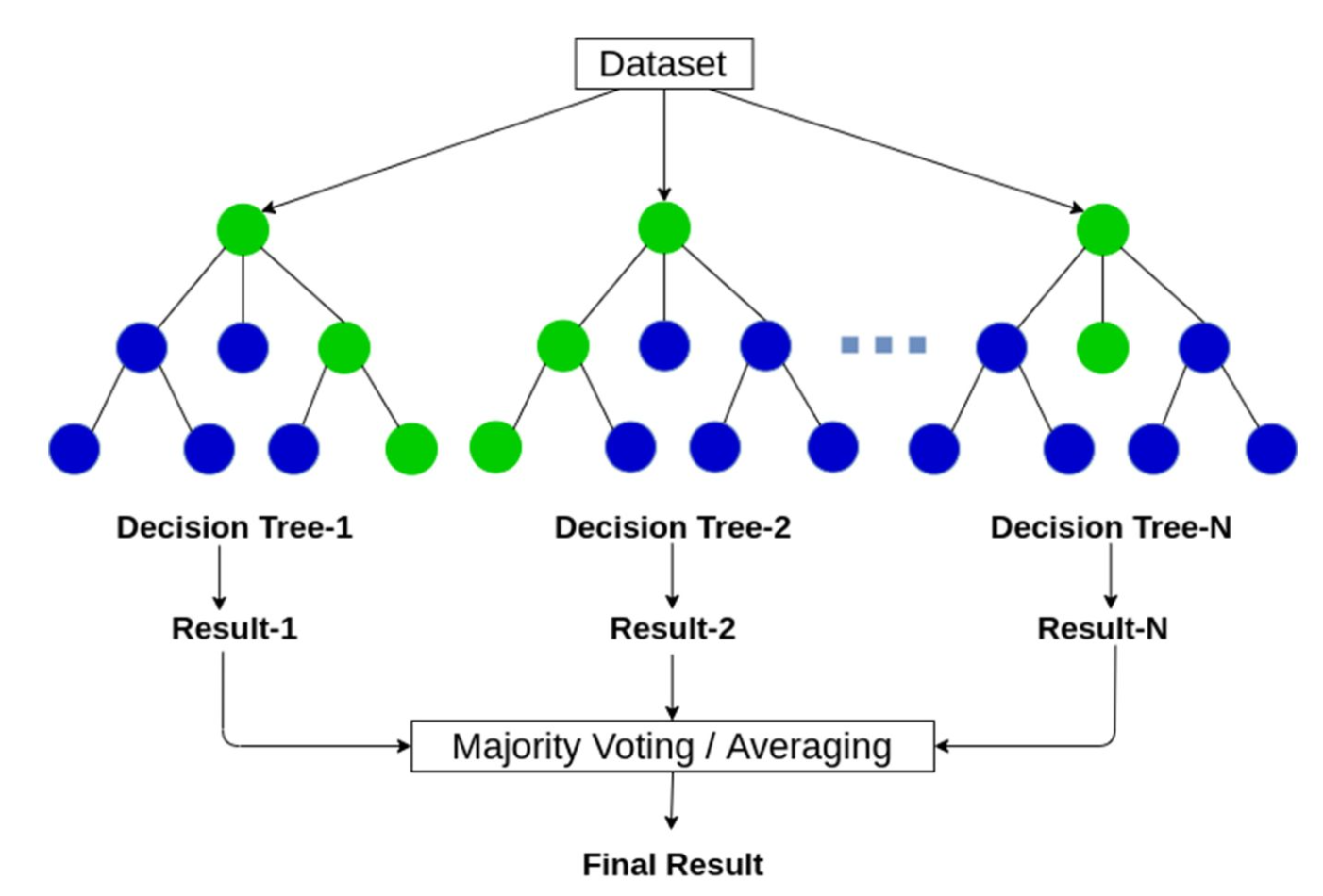
- 동일한 데이터셋에서 $N$개의 부트스트랩을 만듦
- 각각에서 Decision Tree를 학습 (Decision Tree-1, Decision Tree-2, …, Decision Tree-N)
- 각 트리의 예측 결과를 모음
- Majority Voting (분류) 또는 Averaging (회귀)으로 최종 결과 산출
Random Forests
Random Forests는 bagged trees에 약간의 트릭을 추가해서 트리들 사이의 상관관계를 줄임(decorrelate).
- Bagging처럼 부트스트랩 샘플로 여러 decision tree를 학습
- 트리 학습 중 각 split마다 전체 $p$개 predictor 중에서 $m$개의 부분집합만 candidate로 고려함
- 매 split마다 새로운 $m$개의 predictor를 선택
- 일반적으로 $m \approx \sqrt{p}$
예시
1. 원본 데이터 (5 rows × 6 features, 마지막 y가 label)
1
2
3
4
5
6
7
8
9
10
┌────┬────┬────┬────┬────┬────┬──────┐
│ ID │ X₁ │ X₂ │ X₃ │ X₄ │ X₅ │ y │ ← label
├────┼────┼────┼────┼────┼────┼──────┤
│ 1 │ ● │ ● │ ● │ ● │ ● │ A │
│ 2 │ ● │ ● │ ● │ ● │ ● │ B │
│ 3 │ ● │ ● │ ● │ ● │ ● │ A │
│ 4 │ ● │ ● │ ● │ ● │ ● │ B │
│ 5 │ ● │ ● │ ● │ ● │ ● │ A │
└────┴────┴────┴────┴────┴────┴──────┘
p = 5개 feature로 split, m = √5 ≈ 2 (반올림)
2. 부트스트랩으로 데이터셋 3개 만들기
각 row에서 5개씩 복원 추출:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
원본 ID: [1, 2, 3, 4, 5]
│
┌──────────┼──────────┐
▼ ▼ ▼
┌──────┐ ┌──────┐ ┌──────┐
│ D¹ │ │ D² │ │ D³ │
├──────┤ ├──────┤ ├──────┤
│ ID 1 │ │ ID 5 │ │ ID 2 │
│ ID 3 │ │ ID 2 │ │ ID 4 │
│ ID 1 │ │ ID 5 │ │ ID 4 │
│ ID 4 │ │ ID 3 │ │ ID 5 │
│ ID 2 │ │ ID 1 │ │ ID 3 │
└──────┘ └──────┘ └──────┘
(ID 5 (ID 4 (ID 1
빠짐) 빠짐) 빠짐)
3. 각 부트스트랩 데이터셋으로 트리 학습 (split마다 m=2개 feature 랜덤 선택)
트리 1 (D¹로 학습)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[Root split]
후보: {X₁, X₄} 랜덤으로 뽑힘
→ X₄로 split
│
X₄ < 0.5 │ X₄ ≥ 0.5
┌────────┴────────┐
▼ ▼
[Left split] [Right split]
후보: {X₂, X₅} 후보: {X₁, X₃} ← 또 새로 뽑음
→ X₂로 split → X₃로 split
│ │
X₂<0.3 │ X₂≥0.3 X₃<0.7 │ X₃≥0.7
┌────┴────┐ ┌────┴────┐
▼ ▼ ▼ ▼
[A] [B] [A] [B]
트리 2 (D²로 학습)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[Root split]
후보: {X₂, X₃}
→ X₃로 split
│
X₃ < 0.4 │ X₃ ≥ 0.4
┌────────┴────────┐
▼ ▼
[Left split] [Right]
후보: {X₁, X₄} 후보: {X₂, X₅} ← 매 split마다 feature 5개 중 2개를 새로 뽑음
→ X₁로 split → X₅로 split
│ │
┌────┴────┐ ┌────┴────┐
▼ ▼ ▼ ▼
[A] [A] [B] [B]
트리 3 (D³로 학습)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[Root split]
후보: {X₁, X₅}
→ X₁로 split
│
X₁ < 0.6 │ X₁ ≥ 0.6
┌────────┴────────┐
▼ ▼
[Left] [Right split]
후보: {X₃, X₄} 후보: {X₂, X₄}
→ X₃로 split → X₄로 split
│ │
┌────┴────┐ ┌────┴────┐
▼ ▼ ▼ ▼
[B] [A] [B] [A]
- 각 트리가 root에서부터 다른 feature로 split하기 시작했다는 점에 주목
- feature 무작위 선택이 강제한 결과
- Bagging만 했으면 X₃처럼 강력한 feature가 있을 때 세 트리 모두 root에서 X₃를 골랐을 거.
4. 새 데이터로 예측 → Majority Vote
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
새 데이터: x_new = (X₁=0.8, X₂=0.5, X₃=0.3, X₄=0.7, X₅=0.2)
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Tree 1 │ │ Tree 2 │ │ Tree 3 │
│ │ │ │ │ │
│ X₄≥ 0.5 │ │ X₃< 0.4 │ │ X₁≥ 0.6 │
│ → R │ │ → L │ │ → R │
│ X₃< 0.7 │ │ X₁≥ ... │ │ X₄≥ ... │
│ → L │ │ → R │ │ → R │
│ │ │ │ │ │
│ 예측: A │ │ 예측: A │ │ 예측: A │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
└─────────────────┼─────────────────┘
▼
┌───────────────┐
│ Majority Vote │
│ A: 3, B: 0 │
└───────┬───────┘
▼
[최종 예측: A]
왜 효과적인가?
- 만약 어떤 한 feature가 매우 강력하면, bagging만 했을 땐 모든 트리가 그 feature를 root에서 쓰게 되어 트리들끼리 강하게 상관됨.
- Random Forests는 split마다 일부 feature만 보게 하여 트리들이 더 다양해지게 만듦
- Theorem 2에서 본 것처럼 독립성이 높아질수록 결합 모델의 error가 더 줄어들기 때문.
Random Forests 실험
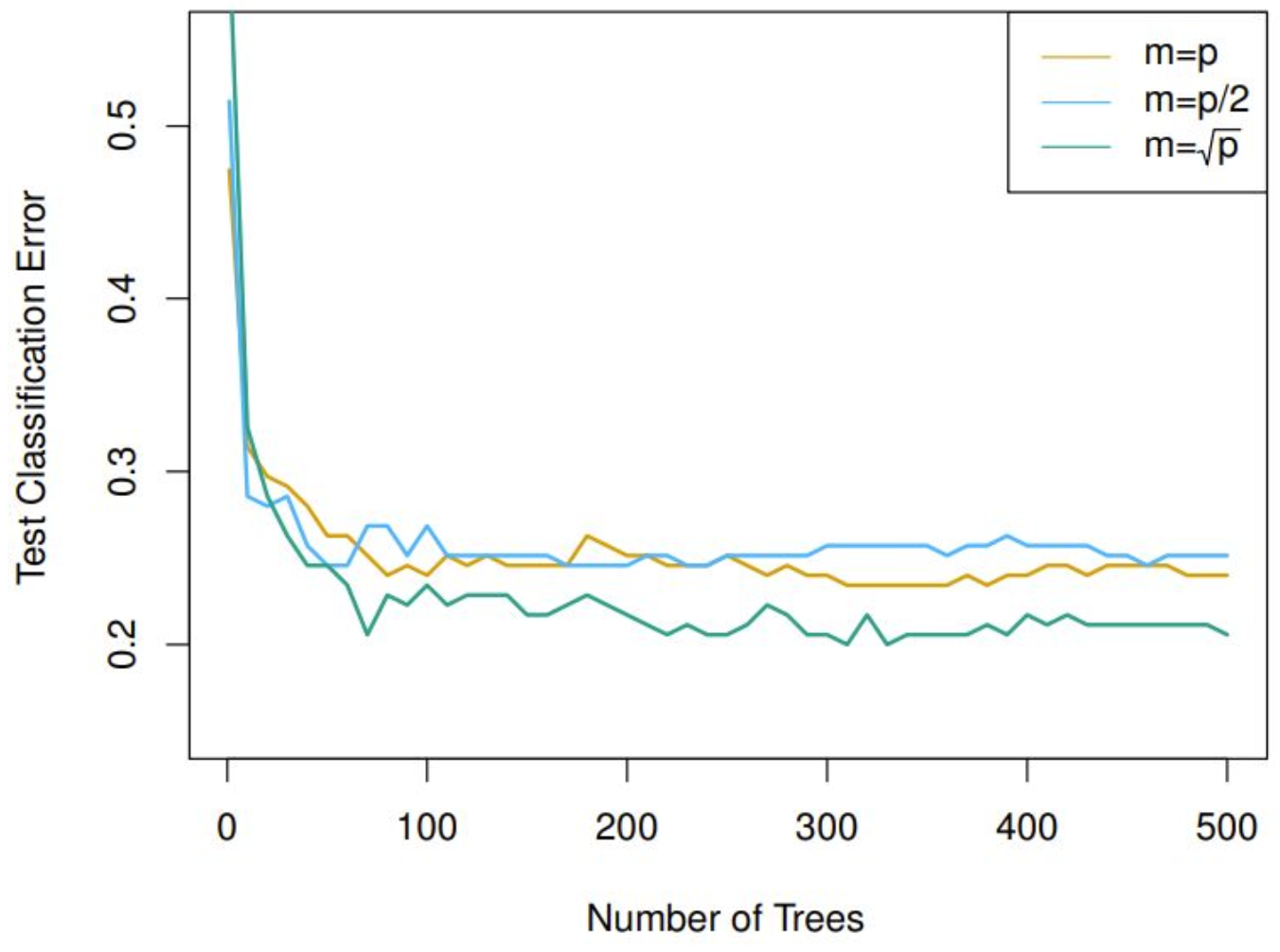
- 실험적으로 $m = p$ (bagging), $m = p/2$, $m = \sqrt{p}$를 비교하면
- $m = \sqrt{p}$일 때 test classification error가 가장 낮음.
- 트리 수가 늘어날수록 error는 빠르게 감소하다가 수렴함.
Boosting
Boosting의 개념
Boosting도 bagging처럼 회귀나 분류에 폭넓게 적용 가능한 일반적 접근.
차이점:
- Bagging은 각 모델을 독립적인 부트스트랩 데이터로 학습
- Boosting은 모델(weak learner)들을 순차적(sequentially) 으로 학습.
- 각 모델은 이전 모델의 정보를 활용해서 학습됨
Boosting의 전체 흐름
- 랜덤보다 약간만 더 나은 base (weak) learner들을 결합함
- 이전 base learner의 성능을 활용해서 순차적으로 결합
- 현재 모델의 성능에 기반해서 각 training example의 가중치를 재조정 :
- 맞춘 example은 가중치 down
- 틀린 example은 가중치 up (boosted)
- weight를 높인다 = 다음에 그 데이터가 샘플될 확률이 높아진다
- 이 과정을 반복해서 여러 base learner를 학습하고 전체 성능 측정
- 앞의 모델들이 못 맞췄던 데이터에 대해서 점점 잘 맞추게 됨
- 모든 base learner를 선형결합, 가중치는 각 learner의 성능에 비례
- 성능 좋은 learner는 높은 weight
- 낮은 learner는 낮은 weight
Boosting for Classification: AdaBoost
Input:
- training dataset {${\mathbf{x}_i, \mathbf{y}_i}$} for $i = 1, \ldots, n$, $\mathbf{y} \in {-1, +1}$
알고리즘:
- $D_1(i) = 1/n$로 초기화 (uniform distribution)
- for $t = 1, \ldots, T$:
- $D_t$로 base learner $h_t: \mathbf{x} \to {+1, -1}$ 학습
- $\epsilon_t = p_{D_t}[h_t(\mathbf{x}_i) \neq \mathbf{y}_i]$
- 현재 분포 $D_t$ 하에서의 error rate
- $\alpha_t = \frac{1}{2} \log \frac{1 - \epsilon_t}{\epsilon_t}$
- log(success rate / error rate)
- $\epsilon_t \to 1$ : 거의 다 틀림. $\alpha_t \to - \infty$
- $\epsilon_t \to 0$ : 거의 다 맞음. $\alpha_t \to + \infty$
- $\epsilon_t = 0.5$ : 50% 맞음. $\alpha_t = 0$
- $\forall i\ D_{t+1}(i) = D_t(i) e^{-\alpha_t \mathbf{y}_i h_t(\mathbf{x}_i)}$
- $h_t$가 맞았으면 $\mathbf{y}_i h_t(\mathbf{x}_i) > 0$
- $h_t$가 틀렸으면 $\mathbf{y}_i h_t(\mathbf{x}_i) < 0$
- 다음 데이터 분포 : 맞은 데이터에 대해서 가중치 감소, 틀린 데이터에 대해서 가중치 증가
- $\forall i\ D_{t+1}(i) = \frac{D_{t+1}(i)}{\sum_{j=1}^{n} D_{t+1}(j)}$
- 합이 1이 되도록 정규화
- Output: $H(x) = \mathrm{sign}\left(\sum_{t=1}^{T} \alpha_t h_t(\mathbf{x})\right)$
- $h_t$는 +1, -1 출력
- 가중합에 대한 가중치 : $\alpha_t$
- 가중합의 부호가 (+) 이면 $H(x)$ 예측값 1
- 가중합의 부호가 (-) 이면 $H(x)$ 예측값 -1
Base Learner 조건
- $\alpha_t > 0$ : success > error
- $\alpha_t = 0$ : success = error
- $\alpha_t < 0$ : success < error
- 따라서 base classifier는 최소 50% success rate여야 boosting이 의도대로 작동함 (아니면 가중치가 반대로 업데이트됨)
- Base learner로는 어떤 classifier도 가능하지만, decision tree나 decision stump (단일 노드 트리)가 많이 쓰임
- Boosting 모델은 보통 overfitting에 강건한 편
예시
10개 샘플 (양성 5개, 음성 5개)에 대해서
$t = 1$:
- 모든 샘플 가중치 $D_1(i) = 1/10$로 시작.
- 세로 decision stump로 분류 → 3개 틀림 → $\epsilon_1 = 0.3$, $\alpha_1 = \frac{1}{2}\log\frac{0.7}{0.3} \approx 0.42$.
- 틀린 3개 샘플의 가중치를 키움.
$t = 2$:
- 새 분포 $D_2$에서 base learner 학습.
- 가중치 큰 3개는 맞히고 가중치 작은 3개는 틀림 → $\epsilon_2 = 0.21$, $\alpha_2 \approx 0.65$
- 이전보다 더 큰 신뢰도
$t = 3$:
- 다시 분포 업데이트.
- 틀린 3개가 작은 가중치만 가져서 $\epsilon_3 = 0.14$, $\alpha_3 \approx 0.92$.
최종 출력:
\[H(x) = \mathrm{sign}\left(0.42 \times h_1(\mathbf{x}) + 0.65 \times h_2(\mathbf{x}) + 0.92 \times h_3(\mathbf{x})\right)\]각각 단순한 decision stump지만, 가중합한 결과는 복잡한 결정 경계를 만들어 모든 샘플을 올바르게 분류함.
AdaBoost와 Stagewise Selection의 관계
AdaBoost는 stagewise feature selection을 떠올리게 함.
- Stagewise selection의 $k$번째 step: \(\sum_{i=1}^{k-1} \beta_i f_i(\mathbf{x}) + \beta_k f_k(\mathbf{x})\)
- AdaBoost의 $k$번째 step: \(\sum_{i=1}^{t-1} \alpha_i h_i(\mathbf{x}) + \alpha_k h_k(\mathbf{x})\)
형태가 동일함. 둘이 어떤 관계가 있을까?
AdaBoost = Stagewise Additive Learning with Exponential Loss
Exponential loss를 사용한 stagewise additive learning이 사실 AdaBoost와 동일함을 증명할 수 있음.
- 매 step에서 misclassification rate를 최소화.
Exponential loss :
\[\mathrm{argmin}_{(\alpha_t, h_t)} \sum_{i=1}^{n} e^{-\mathbf{y}f(\mathbf{x})}\]여기서 $f(\mathbf{x}) = \sum_{j=1}^{t-1}\alpha_j h_j(\mathbf{x}) + \alpha_t h_t(\mathbf{x})$ (stagewise)이므로:
\[= \mathrm{argmin}_{(\alpha_t, h_t)} \sum_{i=1}^{n} e^{-\sum_{j=1}^{t-1}\mathbf{y}_i \alpha_j h_j(\mathbf{x}_i) - \mathbf{y}_i \alpha_t h_t(\mathbf{x}_i)}\]지수 분리:
\[= \mathrm{argmin}_{(\alpha_t, h_t)} \sum_{i=1}^{n} \underbrace{e^{-\sum_{j=1}^{t-1}\mathbf{y}_i \alpha_j h_j(\mathbf{x}_i)}}_{\equiv D_t(i)} \cdot e^{-\mathbf{y}_i \alpha_t h_t(\mathbf{x}_i)}\]앞쪽 부분을 step $t$에서의 분포 $D_t(i)$로 정의:
\[= \mathrm{argmin}_{(\alpha_t, h_t)} \sum_{i=1}^{n} D_t(i) e^{-\mathbf{y}_i \alpha_t h_t(\mathbf{x}_i)}\]이제 맞은 example과 틀린 example로 분리:
\[= \mathrm{argmin}_{(\alpha_t, h_t)} \sum_{\mathbf{y}_i = h_t(\mathbf{x}_i)} D_t(i) e^{-\mathbf{y}_i \alpha_t h_t(\mathbf{x}_i)} + \sum_{\mathbf{y}_i \neq h_t(\mathbf{x}_i)} D_t(i) e^{-\mathbf{y}_i \alpha_t h_t(\mathbf{x}_i)}\]$\mathbf{y}_i h_t(\mathbf{x}_i) = 1$ (correct) 또는 $-1$ (incorrect)이므로:
\[= \mathrm{argmin}_{(\alpha_t, h_t)} \sum_{\mathbf{y}_i = h_t(\mathbf{x}_i)} D_t(i) e^{-\alpha_t} + \sum_{\mathbf{y}_i \neq h_t(\mathbf{x}_i)} D_t(i) e^{\alpha_t}\]전체 합으로 다시 쓰기 위해 $\sum_{\text{correct}} = \sum_{\text{all}} - \sum_{\text{incorrect}}$:
\[= \mathrm{argmin}_{(\alpha_t, h_t)}\ e^{-\alpha_t} \sum_{i=1}^{n} D_t(i) + (e^{\alpha_t} - e^{-\alpha_t}) \sum_{i=1}^{n} D_t(i) I(\mathbf{y}_i \neq h_t(\mathbf{x}_i))\]결국 이 값을 minimize 하고 싶음.
minimize 하기 위한 $\alpha_t$, $h_t$를 구하고 싶음.
이를 $\alpha_t$로 편미분해서 0으로 두면:
\[-e^{-\alpha_t} \sum_{i=1}^{n} D_t(i) + (e^{\alpha_t} + e^{-\alpha_t}) \sum_{i=1}^{n} D_t(i) I(\mathbf{y}_i \neq h_t(\mathbf{x}_i)) = 0\] \[e^{-\alpha_t} \sum_{i=1}^{n} D_t(i) = (e^{\alpha_t} + e^{-\alpha_t}) \sum_{i=1}^{n} D_t(i) I(\mathbf{y}_i \neq h_t(\mathbf{x}_i))\]양변을 정리:
\[\frac{e^{-\alpha_t}}{e^{\alpha_t} + e^{-\alpha_t}} = \underbrace{\frac{\sum_{i=1}^{n} D_t(i) I(\mathbf{y}_i \neq h_t(\mathbf{x}_i))}{\sum_{i=1}^{n} D_t(i)}}_{= \epsilon_t \text{ (step } t \text{ misclassification rate)}}\]- 틀린 데이터 분포 합 / 모든 데이터 샘플 분포 합 = error rate
좌변을 $e^{\alpha_t}$로 정리:
\[\epsilon_t = \frac{e^{-\alpha_t}}{e^{\alpha_t} + e^{-\alpha_t}} = \frac{1}{e^{2\alpha_t} + 1}\] \[e^{2\alpha_t} + 1 = \frac{1}{\epsilon_t} \implies e^{2\alpha_t} = \frac{1 - \epsilon_t}{\epsilon_t}\] \[\boxed{\alpha_t = \frac{1}{2} \log \frac{1 - \epsilon_t}{\epsilon_t}}\]이건 정확히 AdaBoost의 $\alpha_t$ 정의와 같음
또, $D_{t+1}(i)$를 보면:
\[D_{t+1}(i) = e^{-\sum_{j=1}^{t} \mathbf{y}_i \alpha_j h_j(\mathbf{x}_i)} = e^{-(\sum_{j=1}^{t-1} \mathbf{y}_i \alpha_j h_j(\mathbf{x}_i) + \mathbf{y}_i \alpha_t h_t(\mathbf{x}_i))} = D_t(i) e^{-\mathbf{y}_i \alpha_t h_t(\mathbf{x}_i)}\]이것도 AdaBoost의 가중치 업데이트 식과 완전히 동일.
결론
$D_t(i)$, $\alpha_t$, $\epsilon_t$의 정의 모두 AdaBoost와 동치.
AdaBoost는 exponential loss를 사용하는 stagewise additive learning
Boosting for Regression
회귀에서의 Boosting
회귀에서의 boosting은 분류보다 더 직관적
- 매 step에서 현재 모델의 residual (정답 - 예측) 에 새 base 모델을 fit
- 새 base learner는 residual이 큰 example에 더 집중함 (이전 모델의 실수를 보완)
- 분류에서의 $D_t(i)$와 비슷하게, step $t$에서 residual $r_t(i)$를 추적
- 새 decision tree를 fitted function에 더해서 residual을 업데이트
Residual-based Learning 알고리즘
Input:
- training dataset ${\mathbf{x}_i, \mathbf{y}_i}$ for $i = 1, \ldots, n$
알고리즘:
- $f(\mathbf{x}) = 0$, $r_1(i) = \mathbf{y}_i$로 초기화
- 맞춰야 하는 residual이 처음에는 전체 $\mathbf{y}_i$ (아무도 안 풀었으니 남은 일감 = 정답 그 자체)
- for $t = 1, 2, \ldots, T$:
- 대체 학습 데이터 ${\mathbf{x}_i, r_t(i)}$로 base learner $f_t$ 학습
- 원래 정답이 아니라 현재 남은 residual을 새 타겟으로 두고 학습
- 모델 업데이트: $f(\mathbf{x}) \leftarrow f(\mathbf{x}) + \lambda f_t(\mathbf{x})$
- 이번 learner가 처리한 만큼 누적 예측에 더함
- residual 업데이트: $r_{t+1}(i) = r_t(i) - \lambda f_t(\mathbf{x}_i)$
- 이번에 처리한 만큼 남은 일감에서 빼
- 다음 step의 learner가 맞춰야 하는 대상이 줄어들어
- 대체 학습 데이터 ${\mathbf{x}_i, r_t(i)}$로 base learner $f_t$ 학습
Output:
- $f(\mathbf{x}) = \lambda(f_1(\mathbf{x}) + \ldots + f_T(\mathbf{x}))$
Shrinkage Parameter $\lambda$
- $0 \leq \lambda \leq 1$: 학습 속도를 늦춰서 더 많은 / 다양한 base learner들이 residual을 공격하게 함
- $\lambda$가 작으면 한 번에 너무 빨리 residual을 줄이지 않고 천천히 줄여나감 → 일반화 성능에 도움
- Base learner로는 분류 때와 마찬가지로 decision tree 또는 decision stump가 널리 쓰임
예시
셋업
집값 예측 문제라고 하자. 데이터 포인트 하나만 보면 (이해를 위해), 실제 집값 $y = 8$ (억).
$\lambda = 1$로 두고 시작.
초기화: $t = 0$
- $f(\mathbf{x}) = 0$ (아직 아무 예측도 안 함)
- $r_1 = y - f(\mathbf{x}) = 8 - 0 = 8$
- “내가 맞춰야 할 정답”이 처음엔 그냥 $y$ 그 자체
Step $t = 1$
학습 데이터: $(\mathbf{x}, r_1) = (\mathbf{x}, 8)$
→ base learner $f_1$이 8을 예측하려 시도. weak learner라 정확히 못 맞히고 $f_1(\mathbf{x}) = 7.7$ 출력.
업데이트:
- $f(\mathbf{x}) \leftarrow 0 + 1 \cdot 7.7 = 7.7$
- $r_2 = r_1 - \lambda f_1(\mathbf{x}) = 8 - 7.7 = 0.3$
- 첫 모델이 7.7만큼 처리했으니, 남은 일감(residual)은 0.3.
1
2
3
4
5
6
7
8
9
10
11
12
실제 정답 y = 8
┌──────────────┐
│ 아직 처리 안 │
│ 된 부분 │
│ (residual) │
│ 0.3 │
┌─────────────────────────────┼──────────────┤
│ │ │
│ f₁이 처리한 부분 │ ??? │
│ 7.7 │ │
│ │ │
0 ──────┴─────────────────────────────┴──────────────┘ 8
Step $t = 2$
이제 학습 데이터를 바꿔치기함: $(\mathbf{x}, r_2) = (\mathbf{x}, 0.3)$
- $f_2$는 0.3을 예측하려고 학습. 같은 입력 $\mathbf{x}$에 대해 0.3을 출력하도록.
- 다시 weak learner라 못 정확히 못 맞히고 $f_2(\mathbf{x}) = 0.25$ 출력.
업데이트:
- $f(\mathbf{x}) \leftarrow 7.7 + 0.25 = 7.95$
- $r_3 = 0.3 - 0.25 = 0.05$
1
2
3
4
5
6
7
0 ──────┬─────────────────────────────┬──────┬──────┐ 8
│ │ │ │
│ f₁ : 7.7 │ f₂ │ 남은 │
│ │ :0.25│ 0.05 │
│ │ │ │
└─────────────────────────────┴──────┴──────┘
◄─────── f(x) = 7.95 ──────────────►
Step $t = 3$
학습 데이터: $(\mathbf{x}, 0.05)$ → $f_3$는 0.05를 예측하려고 학습. $f_3(\mathbf{x}) = 0.04$ 출력 가정.
- $f(\mathbf{x}) = 7.95 + 0.04 = 7.99$
- $r_4 = 0.05 - 0.04 = 0.01$
핵심 직관
각 learner는 이전 모델들이 다 못 끝낸 일감만 처리함:
| step $t$ | 처리할 일감 ($r_t$) | $f_t$가 처리한 양 | 누적 예측 $f(\mathbf{x})$ | 남은 일감 ($r_{t+1}$) |
|---|---|---|---|---|
| 1 | 8.00 (= 원본 y) | 7.7 | 7.70 | 0.30 |
| 2 | 0.30 | 0.25 | 7.95 | 0.05 |
| 3 | 0.05 | 0.04 | 7.99 | 0.01 |
| 4 | 0.01 | 0.008 | 7.998 | 0.002 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
전체 예측은 모든 처리량의 합:
\[f(\mathbf{x}) = f_1(\mathbf{x}) + f_2(\mathbf{x}) + f_3(\mathbf{x}) + \cdots = 7.7 + 0.25 + 0.04 + \cdots \to 8\]왜 이렇게 하는가
만약 첫 번째 learner $f_1$이 처음부터 8을 정확히 맞히려고 학습한다면 overfitting하거나 학습 자체가 어려움.
대신 weak learner들을 여러 개 두고, 각자 조금씩만 일감 줄이게 하고 싶음.
- Bagging: “100명에게 같은 문제 풀게 하고 평균내자”
- Boosting: “1명이 풀고 → 그 사람이 틀린 부분만 다음 사람이 풀고 → 또 틀린 부분 다음 사람이 풀고…”
Shrinkage $\lambda$의 역할
위에선 $\lambda = 1$로 했는데, 실제론 $\lambda$를 0.1처럼 작게 씀.
그러면 step 1에서 $f_1(\mathbf{x}) = 7.7$이라도:
- $f(\mathbf{x}) = 0 + 0.1 \cdot 7.7 = 0.77$
$r_2 = 8 - 0.77 = 7.23$ ← 여전히 큰 residual
- 남은 일감이 천천히 줄어드니까 더 많은 step이 필요하지만 더 다양한 learner들이 잔여를 공격할 기회가 생김.
- 학습률(learning rate)처럼 한 번에 다 처리하지 말고 야금야금 진행
요약
- Decision tree는 단순하고 해석 가능한 모델이지만, 예측 정확도에서는 다른 방법에 비해 떨어지는 경우가 많음
- Bagging, Random Forests, Boosting은 트리의 예측 정확도를 향상시키는 좋은 방법들임
- 많은 트리를 학습하고 그 예측을 결합하는 방식
- Random Forests와 Boosting은 supervised learning에서 state-of-the-art 수준
- 단, 결과 해석이 어려워짐
- 딥러닝 모델은 성능은 더 좋지만 해석 가능성은 더 떨어짐
| 항목 | Bagging | Random Forests | Boosting |
|---|---|---|---|
| 학습 방식 | 병렬, 독립적 | 병렬, 독립적 | 순차적 |
| 데이터 샘플링 | 부트스트랩 | 부트스트랩 | 가중치 업데이트 (재샘플링 또는 가중 학습) |
| 모델 다양성 | 데이터 무작위성으로 확보 | 데이터 + feature 무작위성 | 이전 모델의 오차에 집중 |
| 결합 방식 | 평균 / 다수결 | 평균 / 다수결 | 가중 합 |
| 주된 효과 | Variance 감소 | Variance 추가 감소 | Bias + Variance 감소 |
| overfitting | Robust | Robust | 비교적 robust하지만 노이즈에 취약할 수 있음 |