[DB] 조인 튜닝
Nested Loops join
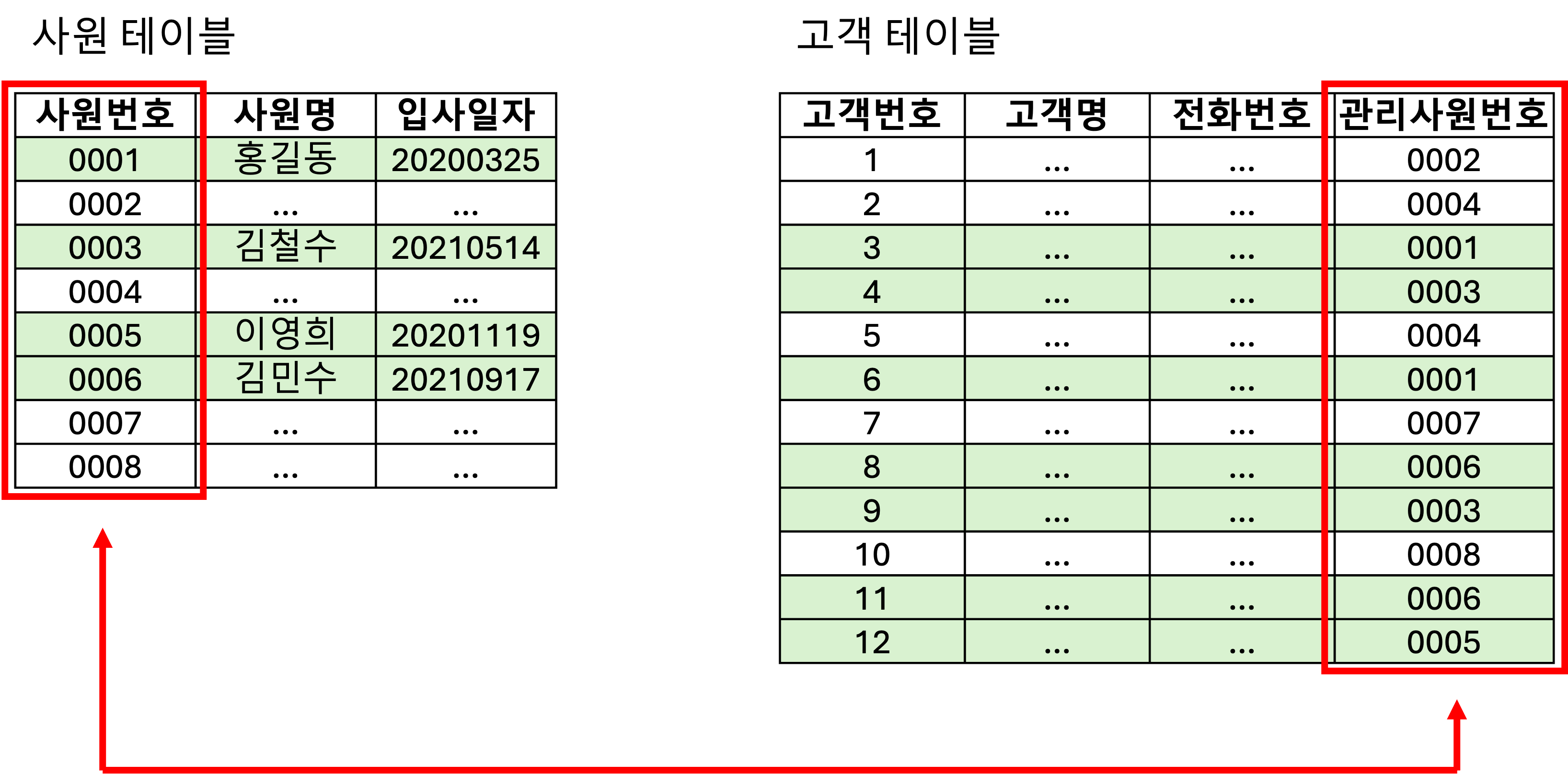
2020년 1월 1일 이후에 입사한 사원이 관리하는 고객 데이터를 추출하고 싶을 때
1
2
3
4
select e.사원명, c.고객명, c.전화번호
from 사원 e, 고객 c
where e.입사일자 >= '20200101'
and c.관리사원번호 = e.사원번호
와 같은 쿼리 사용 가능.
논리적으로 생각했을 때
- 사원 테이블에서 2020년 1월 1일 이후에 입사한 사원 찾아서
- 고객 테이블에서 사원번호가 일치하는 레코드 찾기
$\rightarrow$ NL 조인의 원리
1
2
3
4
5
6
7
8
9
begin
for outer in (select 사원번호, 사원명 from 사원 where 입사일자 >= '20200101')
loop
for inner in (select 고객명, 전화번호 from 고객 where 관리사원번호 = outer.사원번호)
loop
dbms_output.put_line(outer.사원명 || ' : ' || inner.고객명 || ' : ' || inner.전화번호);
end loop;
end loop;
end;
일반적으로 NL 조인은 Outer와 Inner 테이블 모두 인덱스 사용.
- Outer 쪽 테이블 사이즈가 크지 않으면 table full scan 해도 됨. 어차피 한 번 돌아.
- Inner 쪽 테이블은 인덱스 사용해야 함. 아니면 Outer loop 횟수만큼 table full scan 해야 함.
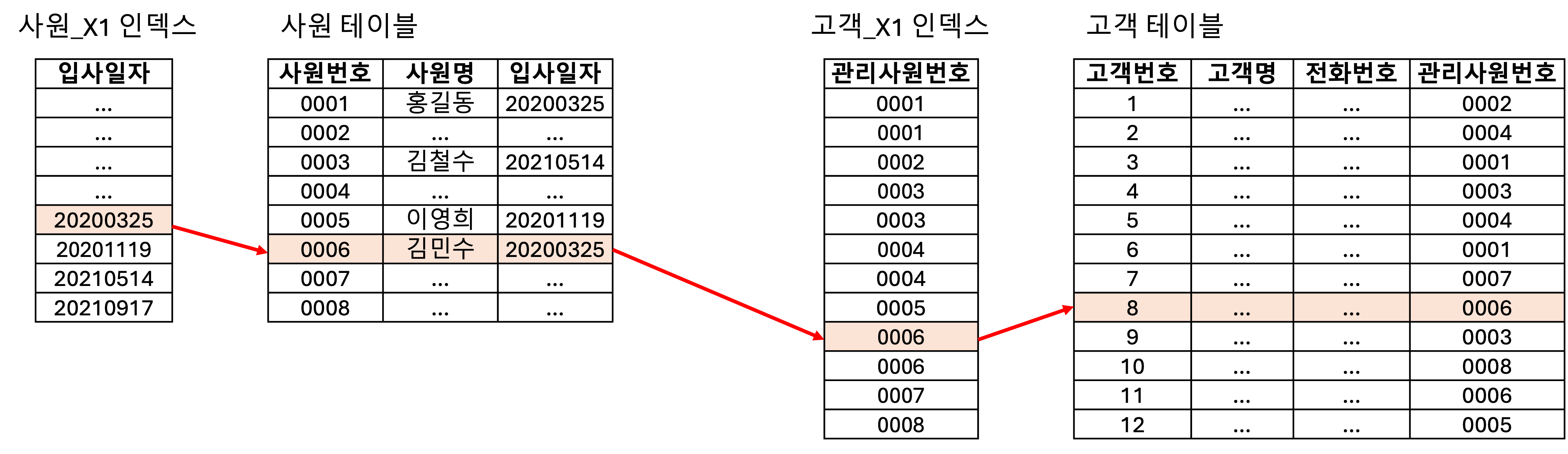
- 사원_X1 인덱스에서 입사일자 >= ‘20200101’인 첫 번째 레코드 찾아
- 인덱스에서 읽은 ROWID로 사원 테이블 레코드 찾아
- 사원 테이블에서 찾은 사원번호로 고객_X1 인덱스 탐색
- 고객_X1 인덱스에서 읽은 ROWID로 고객 테이블 레코드 찾아
- 사원 테이블에서 찾은 사원 번호 끝날때까지 반복
1
2
3
4
5
select /*+ ordered use_nl(c) */
e.사원명, c.고객명, c.전화번호
from 사원 e, 고객 c
where e.입사일자 >= '20200101'
and c.관리사원번호 = e.사원번호
- use_nl 힌트로 nl 지정 가능
- ordered 힌트로 from 절에 기술한 순서대로 조인하라고 지정 가능
- 사원 테이블(outer table) 기준으로 고객 테이블(inner table)을 조인해라
1
2
3
4
5
6
7
8
Execution Plan
-------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 NESTED LOOPS
2 1 TABLE ACCESS (BY INDEX ROWID) OF '사원' (TABLE)
3 2 INDEX (RANGE SCAN) OF '사원_X1' (INDEX)
4 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE)
5 4 INDEX (RANGE SCAN) OF '고객_X1' (INDEX)
- 실행계획에서 각 테이블 액세스 할 때 인덱스를 사용하는 것을 확인할 수 있음
1
2
select /*+ ordered use_nl(B) use_nl(C) use_hash(D) */ *
from A, B, C, D
- A, B, C, D 순서로 조인하되, B, C와 조인할 때는 NL 조인, D와 조인할 때는 해시 조인 해라
1
2
select /*+ leading(C, A, D, B) use_nl(A) use_nl(D) use_hash(B) */ *
from A, B, C, D
- leading 힌트 사용하면 from 절 변경 없이 조인 순서 변경 가능
1
2
select /*+ use_nl(A, B, C, D) */ *
from A, B, C, D
- 네 개 테이블을 NL 방식으로 조인하되, 순서는 옵티마이저가 알아서 정해라
인덱스가 아래와 같이 있을 때
1
2
3
4
5
* 사원_PK : 사원번호
* 사원_X1 : 입사일자
* 고객_PK : 고객번호
* 고객_X1 : 관리사원번호
* 고객_X2 : 최종주문금액
1
2
3
4
5
6
7
8
select /*+ ordered use_nl(c) index(e) index(c) */
e.사원번호, e.사원명, e.입사일자
, c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호 -- ①
and e.입사일자 >= '20200101' -- ②
and e.부서코드 = 'Z123' -- ③
and c.최종주문금액 >= 20000 -- ④
- 두 테이블에 index 힌트 사용
- 인덱스 명은 명시하지 않았으므로 어떤 인덱스를 사용할지는 옵티마이저가 결정
1
2
3
4
5
6
7
8
9
10
---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 58 | 5 |
| 1 | NESTED LOOPS | | 5 | 58 | 5 |
| 2 | TABLE ACCESS BY INDEX ROWID| 사원 | 3 | 20 | 2 |
| 3 | INDEX RANGE SCAN | 사원_X1 | 5 | | 1 |
| 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 5 | 76 | 2 |
| 5 | INDEX RANGE SCAN | 고객_X1 | 8 | | 1 |
---------------------------------------------------------------------
조건절 비교 순서
- ② : 입사일자 >= ‘20200101’ 인 조건을 만족하는 레코드 찾으려고 사원_X1 인덱스 range scan (Id 3)
- ③ : 입사일자 조건을 만족하는 사원 중에서, 사원_X1 인덱스에서 읽은 ROWID로 사원 테이블 액세스 해서 부서코드 = ‘Z123’ 필터 조건 만족하는지 확인 (Id 2)
- ① : 사원 테이블에서 읽은 사원번호로 조인 조건 (c.관리사원번호 = e.사원번호) 만족하는 고객 레코드 찾으려고 고객_X1 인덱스 range scan (Id 5)
- 고객_X1 인덱스에서 관리사원번호 조건 안 맞을 때까지 반복
- ④ : 고객_X1 인덱스에서 읽은 ROWID로 고객 테이블 액세스 해서 최종주문금액 >= 20000 필터 조건 만족하는지 확인 (Id 4)
NL 조인 특징
- 랜덤 액세스 위주의 조인 방식이다
- 랜덤 액세스는 레코드 하나 읽으려고 블록을 통째로 읽음
- 메모리 버퍼에서 읽어도 비효율이 존재
- 조인을 한 레코드씩 순차적으로 진행한다
- 부분범위 처리가 가능하다면 아무리 큰 테이블을 조인하더라도 빠른 응답 속도를 낼 수 있음
- 순차적으류 진행하므로, 먼저 액세스되는 테이블 처리 범위에 의해 전체 일량이 결정된다
- 인덱스 구성 전략이 특히 중요하다
- 조인 칼럼에 대한 인덱스가 있는지 여부, 인덱스의 칼럼이 어떻게 구성되어 있는지에 따라 조인 효율이 크게 달라짐
$\rightarrow$ 소량 데이터를 처리하거나 부분범위 처리가 가능한 OLTP 시스템에 적합
NL join 튜닝
사원_X1 인덱스를 읽고 나서 사원 테이블 액세스
여기서는 단일 칼럼 인덱스를 >= 조건으로 스캔했으므로, 비효율은 없음.
딱 읽는 만큼 테이블 랜덤 액세스.
1
2
3
4
5
6
7
Rows Row Source Operation
----- -----------------------------------------
5 NESTED LOOPS
3 TABLE ACCESS BY INDEX ROWID OF 사원
2780 INDEX RANGE SCAN OF 사원_X1
5 TABLE ACCESS BY INDEX ROWID OF 고객
8 INDEX RANGE SCAN OF 고객_X1
- 사원_X1 인덱스를 스캔하고 나서 사원 테이블 액세스한 게 2780번
- 그 중에 부서코드 = ‘Z123’을 만족하는 레코드는 3개
불필요한 테이블 액세스가 많았음. 테이블을 액세스한 후에 필터링되는 비율이 높다면 인덱스에 테이블 필터 조건 칼럼을 추차하는 걸 고려할 수 있음.
사원_X1 인덱스에 부서코드 칼럼을 추가하고 나면 다음과 같이 불필요한 테이블 액세스 사라짐.
1
2
3
4
5
6
7
Rows Row Source Operation
----- -----------------------------------------
5 NESTED LOOPS
3 TABLE ACCESS BY INDEX ROWID OF 사원
3 INDEX RANGE SCAN OF 사원_X1
5 TABLE ACCESS BY INDEX ROWID OF 고객
8 INDEX RANGE SCAN OF 고객_X1
사원_X1 인덱스에서 입사일자와 부서코드 조건을 필터링한 3개의 결과를 내기 위해서 블록을 다음과 같이 읽음.
1
2
3
4
5
6
7
Rows Row Source Operation
----- -----------------------------------------
5 NESTED LOOPS (cr=112 pr=34 pw=0 time=122 us)
3 TABLE ACCESS BY INDEX ROWID OF 사원 (cr=105 pr=32 pw=0 time=118 us)
3 INDEX RANGE SCAN OF 사원_X1 (cr=102 pr=31 pw=0 time=16)
5 TABLE ACCESS BY INDEX ROWID OF 고객 (cr=7 pr=2 pw=0 time=4 us)
8 INDEX RANGE SCAN OF 고객_X1 (cr=5 pr=1 pw=0 time=0 us)
- 사원_X1 인덱스로부터 읽은 블록이 102개
- 한 블ㄹ록에 레코드 500개 있다고 가정하면, 3건을 얻기 위해 50,000개 레코드를 읽은 것
- 사원_X1 인덱스 칼럼 순서를 [부서코드, 입사일자] 순서로 구성하면 좀 줄일 수 있음
고객_X1 인덱스 탐색
1
2
3
4
5
6
7
Rows Row Source Operation
----- -----------------------------------------
5 NESTED LOOPS (cr=2732 pr=386 pw=0 time=...)
2780 TABLE ACCESS BY INDEX ROWID 사원 (cr=166 pr=2 pw=0 time=...)
2780 INDEX RANGE SCAN 사원_X1 (cr=4 pr=0 pw=0 time=...)
5 TABLE ACCESS BY INDEX ROWID 고객 (cr=2566 pr=384 pw=0 time=...)
8 INDEX RANGE SCAN 고객_X1 (cr=2558 pr=383 pw=0 time=...)
- 사원 테이블을 읽는 부분에서는 비효율 없음.
- 인덱스에서 스캔한 블록 4개. 테이블 액세스하고 필터링되는 레코드도 없음.
- 사원 테이블을 읽고 나서 고객 테이블과 조인하는 횟수가 문제
- 고객_X1 인덱스를 탐색하는 횟수(=조인 액세스 횟수)가 많을 수록 성능 느려짐
- 2780번 조인 시도
- 조인 성공하고 필터링까지 마친 최종 결과집합은 5건
- 조인 순서 변경을 고려해 볼 수 있음. 최종주문금액 조건절에 부합하는 레코드가 별로 없으면 성능 향상할 수 있음.
조인 액세스 횟수는 Outer 테이블 필터링 결과 건수에 의해 결정됨
1
2
3
4
5
6
7
8
9
10
---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 58 | 5 |
| 1 | NESTED LOOPS | | 5 | 58 | 5 |
| 2 | TABLE ACCESS BY INDEX ROWID| 사원 | 3 | 20 | 2 |
| 3 | INDEX RANGE SCAN | 사원_X1 | 5 | | 1 |
| 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 5 | 76 | 2 |
| 5 | INDEX RANGE SCAN | 고객_X1 | 8 | | 1 |
---------------------------------------------------------------------
- 위에서는 부서코드 조건을 만족하는 레코드가 3개 있었음 (실행게획 Id 2) $\rightarrow$ 3번의 조인 시도
- 만약 부서코드 조건을 만족하는 레코드가 10만 건이고 고객_X1 인덱스 depth가 3이면, 인덱스 수직적 탐색에서만 30만 개 블록 읽어야 함
고객_X1 인덱스 읽고 나서 고객 테이블 액세스
- 최종주문금액 >= 20000 조건에 의해 필터링되는 비율이 높다면, 고객_X1 인덱스에 최종주문금액 칼럼을 추가하는 걸 고려할 수 있음
맨 처음 액세스하는 사원_X1 인덱스 결과 건수에 의해 전체 일량이 좌우된다
Sort Merge join
PGA
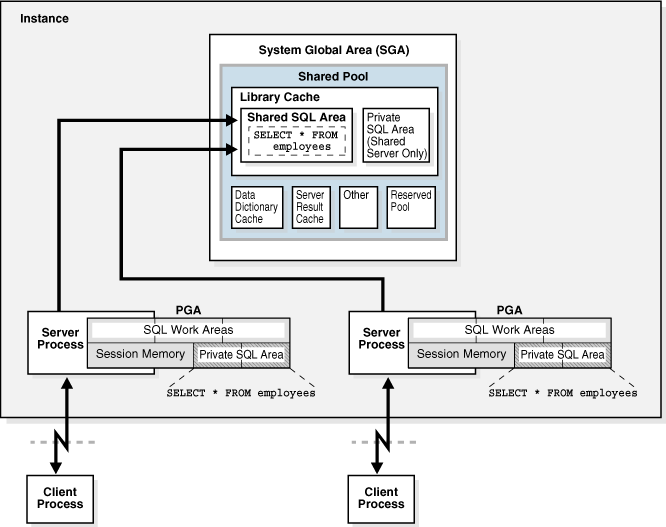
SGA에 캐시된 데이터는 여러 프로세스가 공유.
동시 액세스는 불가하고, latch를 획득하고 블록을 읽기 위한 버퍼 lock도 얻어야 함.
서버 프로세스는 SGA에 공유된 데이터를 읽고 쓰면서, 동시에 자신만의 고유 메모리 영역 PGA를 사용함.
할당받은 PGA 공간이 작아 데이터를 모두 저장할 수 없을 때는 Temp 테이블스페이스를 이용.
PGA는 래치 메커니즘이 필요없어서, SGA 버퍼캐시에서 읽을 때보다 훨씬 빠름.
Sort Merge 조인
- Sort : 양쪽 집합은 조인 칼럼 기준으로 정렬
- Merge : 정렬한 양쪽 집합을 서로 merge
1
2
3
4
5
6
7
8
select /*+ ordered use_merge(c) */
e.사원번호, e.사원명, e.입사일자
, c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '20200101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000
- 사원 데이터를 읽어 조인 칼럼인 사원번호 순으로 정렬
1
2
3
4
5
select 사원번호, 사원명, 입사일자
from 사원
where 입사일자 >= '20200101'
and 부서코드 = 'Z123'
order by 사원번호
- 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장
- 정렬한 결과집합이 PGA에 담을 수 없을 정도로 크면 Temp tablespace에 저장
- 고객 데이터를 읽어 조인칼럼인 관리사원번호 순으로 정렬
1
2
3
4
select 고객번호, 고객명, 전화번호, 최종주문금액
from 고객
where 최종주문금액 >= 20000
order by 관리사원번호
- 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장
- 정렬한 결과집합이 PGA에 담을 수 없을 정도로 크면 Temp tablespace에 저장
- PGA에 저장된 사원 데이터를 스캔하면서 PGA에 저장된 고객 데이터와 조인
begin
for outer in (select * from PGA_saved_사원)
loop
for inner in (select * from PGA_saved_고객 where 관리사원번호 = outer.사원번호)
loop
dbms_output.put_line( ... );
end loop;
end loop;
end;
- 실제 조인 오퍼레이션인 머지 단계는 NL 조인과 다르지 않음

- 사원 데이터를 기준으로 고객 데이터를 매번 full scan 하지 않음.
- 고객 데이터가 정렬되어 있으므로, 조인 대상 레코드를 쉽게 찾고, 조인에 실패하는 레코드를 만나는 순간 멈출 수 있음.
- Sort Area에 저장한 데이터 자체가 인덱스 역할을 함.
- 조인 칼럼에 인덱스가 있어소 NL 조인은 대량 데이터를 조인할 때 불리하므로 소트 머지 조인을 사용할 수 있음.
소트 머지 조인이 빠른 이유
소트 머지 조인은 Sort Area에 미리 정렬해 둔 자료구조를 이용하는 것만 다르고, 조인 프로세스 자체는 NL 조인과 같음.
NL 조인은 ‘인덱스를 이용한 조인’
- 조인 과정에서 액세스하는 모든 블록을 랜덤 액세스 방식으로 건건이 DB 버퍼캐시를 경유해서 읽음
- 읽는 모든 인덱스/테이블 블록에 대해 래치 획득 및 캐시버퍼 체인 스캔 과정을 거침
- 버퍼캐시에서 찾지 못한 블록은 건건이 디스크에서 읽음
소트 머지 조인은 양쪽 테이블로부터 조인 대상 집합을 일괄적으로 읽어 PGA에 저장한 후 조인
- PGA를 읽을 때 래치 획득 과정이 없음
- 조인 전에 양쪽 집합에 대해 소트 연한을 해야 해서 NL 조인보다 느릴 것 같지만, 오히려 빠르게 만드는 핵심
- 소트 머지 조인도 양쪽 테이블로부터 조인 대상 집합을 읽을 때는 DB 버퍼캐시를 경유. 인덱스도 사용.
- 이때 생기는 버퍼캐시 탐색 비용과 랜덤 액세스 부하는 어쩔 수 없음.
소트 머지 조인은 다음과 같은 상황에 주로 사용됨
- 조인 조건식이 등치(=) 조건이 아닌 대량 데이터 조인
- 조인 조건식이 아예 없는 cross join
1
2
3
4
5
6
7
8
9
10
Execution Plan
----------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 MERGE JOIN
2 1 SORT (JOIN)
3 2 TABLE ACCESS (BY INDEX ROWID) OF '사원' (TABLE)
4 3 INDEX (RANGE SCAN) OF '사원_X1' (INDEX)
5 1 SORT (JOIN)
6 5 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE)
7 6 INDEX (RANGE SCAN) OF 고객_X1' (INDEX)
- 양쪽 테이블을 각각 sort 한 후, 위쪽 사원 테이블 기준으로 아래쪽 고객 테이블과 merge join 한다
- 여기서는 인덱스 사용했음. table full scan도 가능.
소트 머지 조인 특징
- 조인을 위해 실시간으로 인덱스를 생성
- 소트 부하만 감수한다면, 건건이 버퍼캐시를 경유하는 NL 조인보다 빠르다
- NL 조인은 조인 칼럼에 대한 인덱스 유무에 영향을 크게 받지만, 소트 머지 조인은 영향을 받지 않음
- 양쪽 집합을 개별적으로 읽고 나서 조인을 시작
- 조인 칼럼에 인덱스가 없는 상황에서 두 테이블을 각각 읽어 조인 대사 집합을 줄일 수 있을 때 유리
- 스캔 위주의 액세스 방식 사용
- 조인 대상 레코드 찾을 때 인덱스 이용할 수도 있음
Hash join
NL 조인은 인덱스에 영향을 많이 받고, 버퍼캐시 히트율에 따라 성능이 들쭉날쭉함.
소트 머지 조인과 해시 조인은 조인 과정에 인덱스를 이용하지 않기 때문에 대량 데이터 조인할 때 NL 조인보다 훨씬 빠르고, 일정한 성능을 보임.
소트 머지 조인은 항상 양쪽 테이블을 정렬하는 부담이 있는데, 해시 조인은 그런 부담도 없음.
해시 조인도 두 단계로 진행됨
- Build : 작은 쪽 테이블(Build Input)을 읽어 해시 테이블(해시 맵)을 생성
- Probe : 큰 쪽 테이블(Probe Input)을 읽어 해시 테이블을 탐색하면서 조인
1
2
3
4
5
6
7
8
select /*+ ordered use_hash(c) */
e.사원번호, e.사원명, e.입사일자
, c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '20200101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000
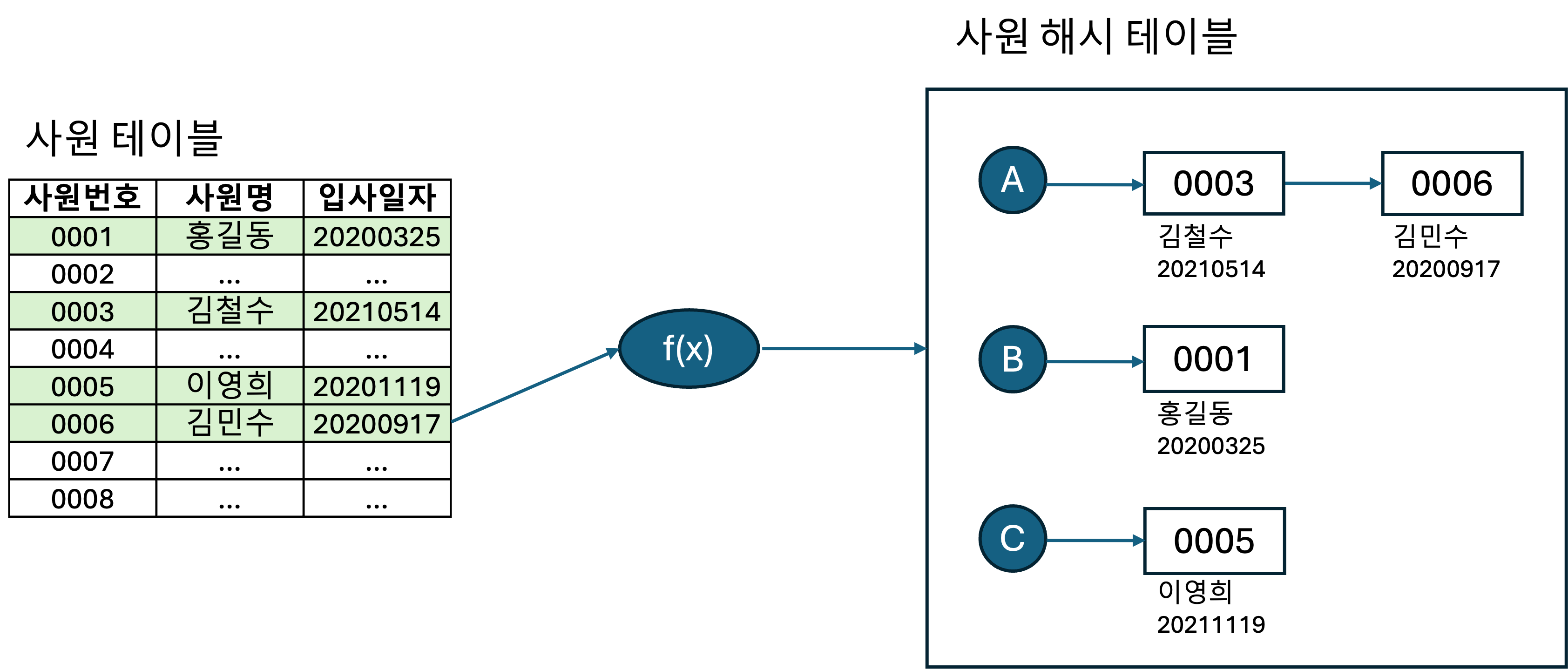
- Build 단계 : 조건에 해당하는 사원 데이터를 읽어 해시 테이블 생성
- 조인칼럼인 사원번호를 해시 테이블 키 값으로 사용
- 사원번호를 해시 함수에 넣어서, 반환값으로 해시 체인을 찾고, 해당 해시 체인에 데이터 연결
- 해시 테이블은 PGA 영역에 할당된 Hash Area에 저장
- 해시 테이블이 너무 커서 PGA에 담을 수 없으면 temp 테이블스페이스에 저장
1
2
3
4
select 사원번호, 사원명, 입사일자
from 사원
where 입사일자 >= '20200101'
and 부서코드 = 'Z123'
- Probe 단계 : 조건에 해당하는 고객 데이터를 하나씩 읽으면서, 앞서 생성한 해시 테이블을 탐색
- 관리사원번호를 해시 함수에 입력해서 반환값으로 해시 체인을 찾고, 해당 체인을 스캔해서 사원번호를 찾아
- 찾으면 조인에 성공, 못 찾으면 조인 실패
1
2
3
select 고객번호, 고객명, 전화번호, 최종주문금액
from 고객
where 최종주문금액 >= 20000
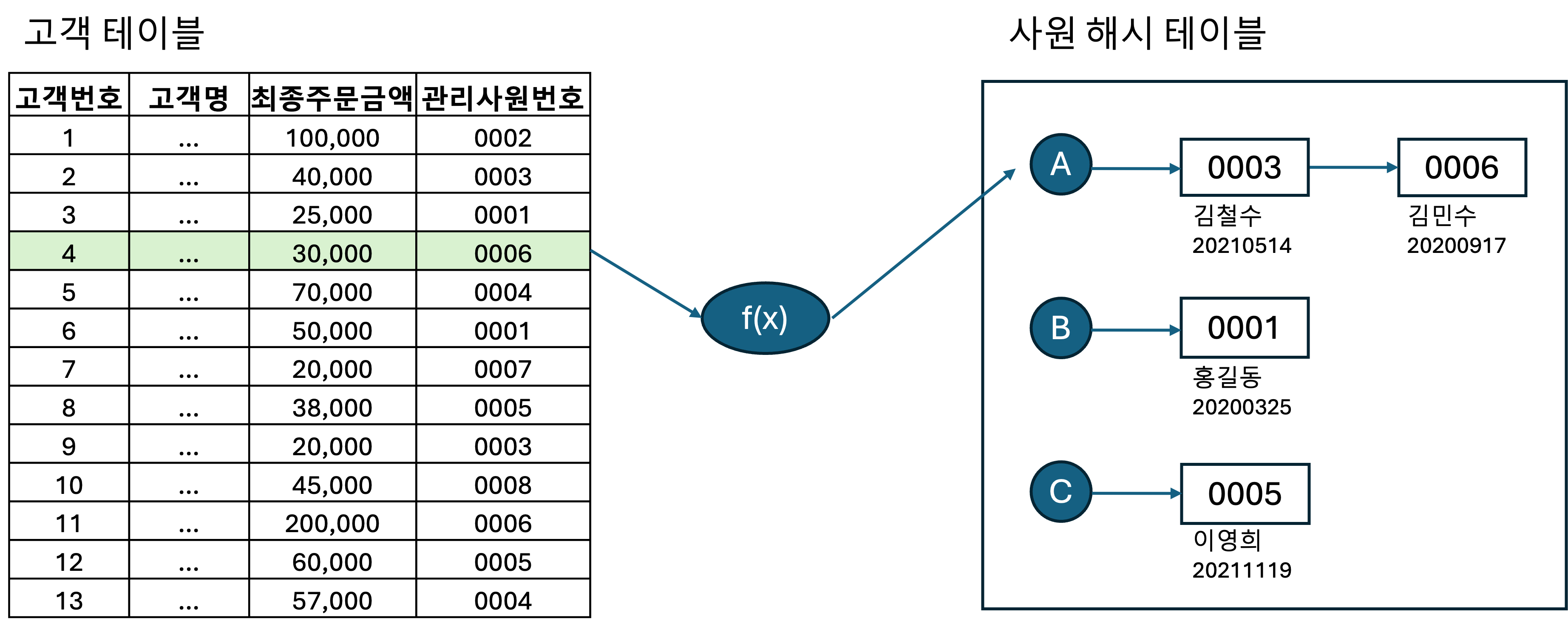
1
2
3
4
5
6
7
8
9
10
11
begin
for outer in (select 고객번호, 고객명, 전화번호, 최종주문금액, 관리사원번호
from 고객 where 최종주문금액 >= 20000)
loop
for inner in (select 사원번호, 사원명, 입사일자 from PGA_saved_사원_hash_map
where 사원번호 = outer.관리사원번호)
loop
dbms_output.put_line(...);
end loop;
end loop;
end;
- 사실상 NL 조인과 다르지 않음
해시 조인이 빠른 이유
해시 조인이 NL 조인보다 빠른 이유는 소트 머지 조인과 같음. 해시 테이블을 PGA 영역에 할당하기 때문.
해시 조인도 Build Input과 Probe Input 각 테이블을 읽을 때는 DB 버퍼캐시 경유.
인덱스도 사용. 이때 생기는 버퍼캐시 탐색 비용과 랜덤 액세스 부하는 피할 수 없음.
대량 데이터를 조인할 때 일반적으로 해시 조인이 소트 머지 조인보다 빠름
- 둘 다 PGA에서 조인 처리
- PGA에서 데이터를 탐색하는 알고리즘 차이에 의한 효과는 미미
- 소트 머지 조인은 ‘양쪽’ 집합을 모두 정렬해서 PGA에 저장
- PGA는 메모리 공간이 그렇게 크지 않아서 Temp 테이블스페이스(디스크)에 쓰는 작업을 수반
- 해시 조인은 ‘한쪽’을 읽어서 해시 맵을 생성
- 작은 집합을 해시 맵 Build Input으로 선택하므로, 두 집합 모두 Hash Area에 담을 수 없을 정도로 큰 경우가 아니면 Temp 테이블스페이스에 쓸 일이 잘 일어나지 않음
대용량 Build Input 처리
만약 두 테이블 모두 대용량 테이블이어서 인메모리 해시 조인이 불가능하면 Divide & Conquer.
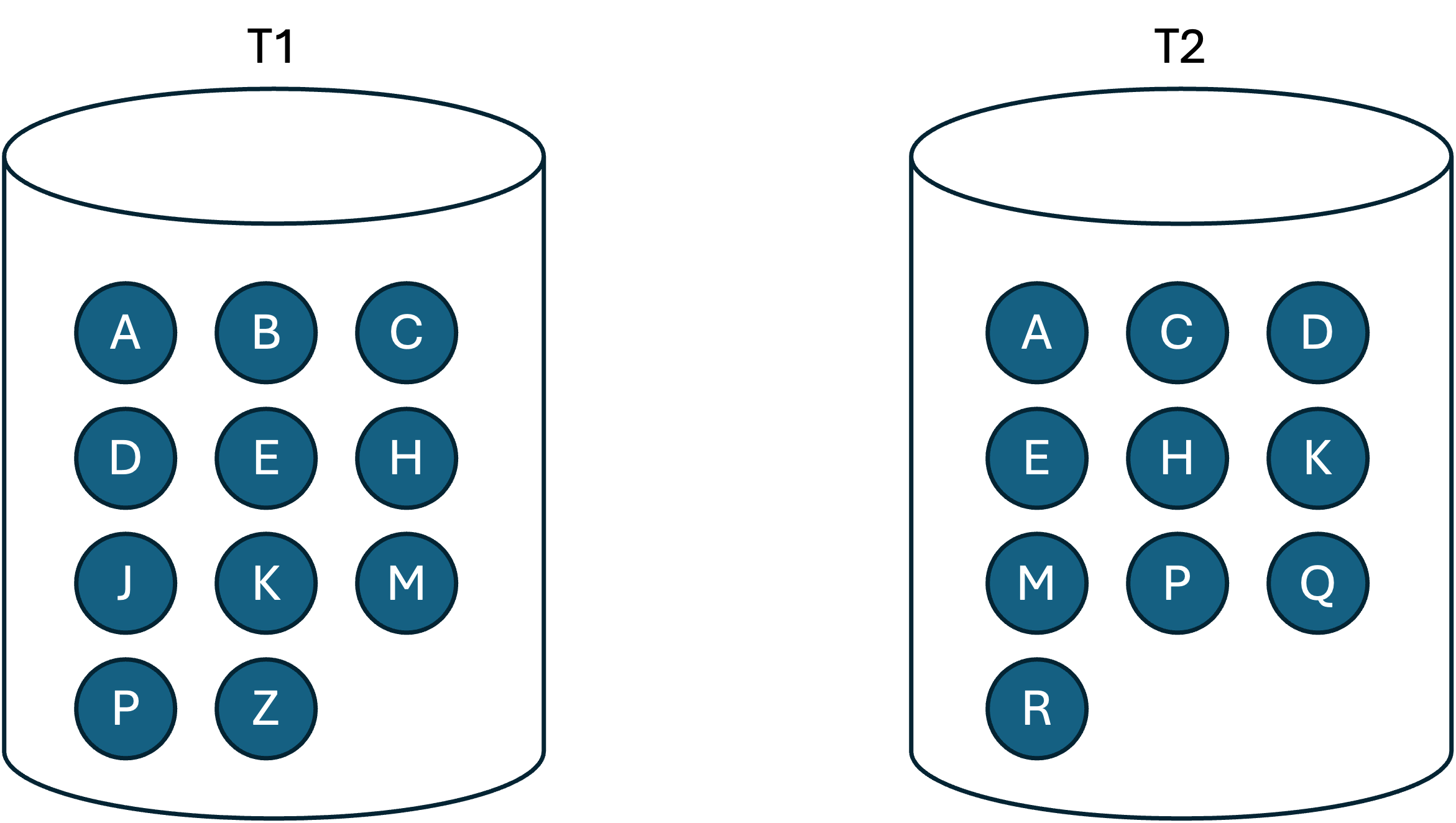
- 파티션
- 조인하는 양쪽 집합의 조인 칼럼에 해시 함수를 적용하고, 반환된 해시 값에 따라 동적으로 파티셔닝
- 양쪽 집합(T1, T2)을 읽어 디스크 Temp 공간에 저장
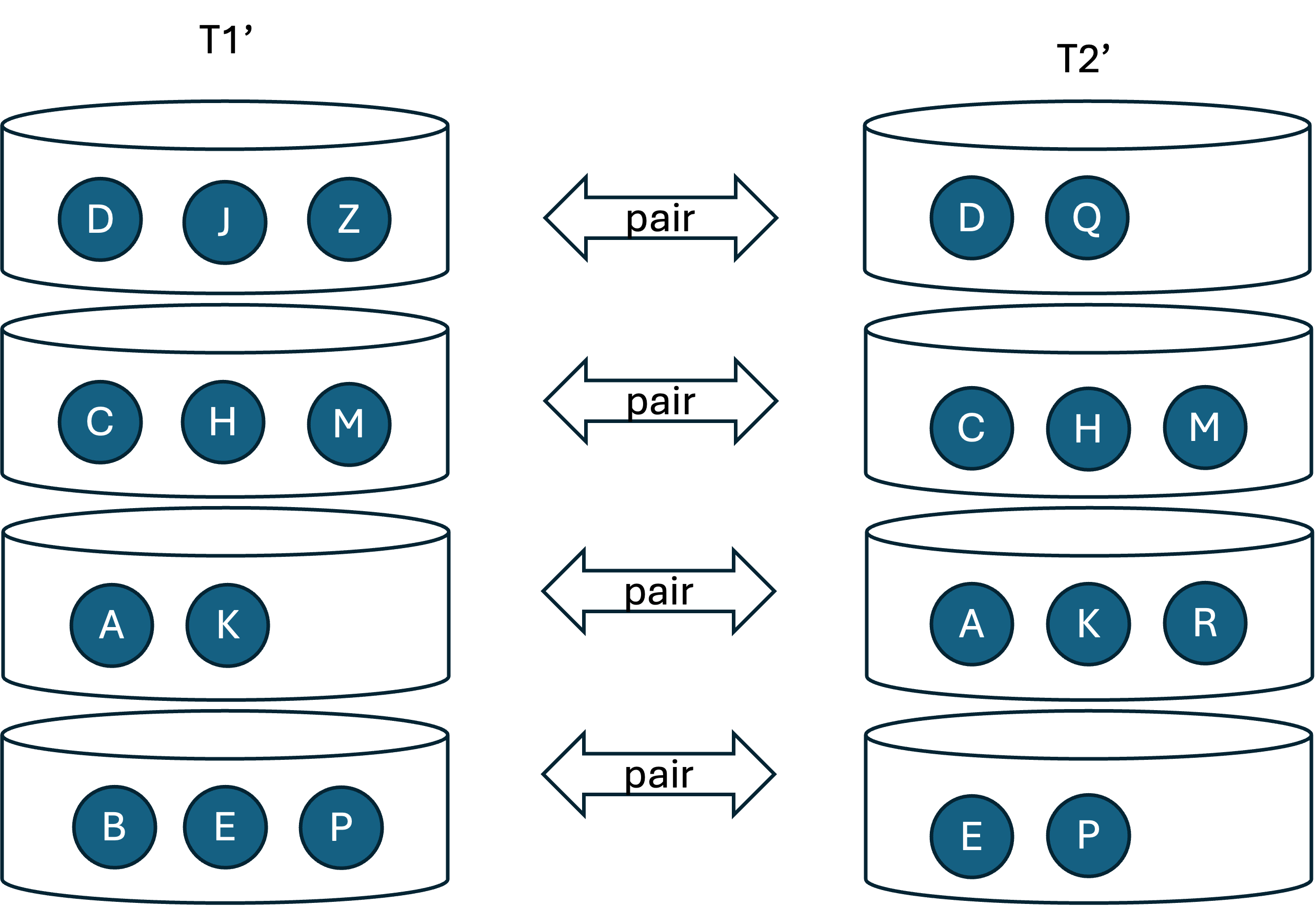
- 조인
- 각 파티션 pair에 대해 하나씩 조인 수행
- 각각에 대한 Build Input과 Probe Input은 독립적으로 결정됨
- 해시 테이블 생성 후, 반대쪽 파티션 로우를 하나씩 읽으면서 해시 테이블을 탐색
해시 조인 제어
1
2
3
4
5
6
7
8
Execution Plan
----------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 HASH JOIN
2 1 TABLE ACCESS (BY INDEX ROWID) OF '사원' (TABLE)
3 2 INDEX (RANGE SCAN) OF '사원_X1' (INDEX)
4 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE)
5 4 INDEX (RANGE SCAN) OF '고객_N1' (INDEX)
- 위쪽 사원 데이터(Build Input)로 해시 테이블 생성
- 아래쪽 고객 테이블(Probe Input)에서 읽은 조인 키값으로 해시 테이블 탐색하면서 조인
1
2
3
4
5
6
7
8
select /*+ use_hash(e c) */
e.사원번호, e.사원명, e.입사일자
, c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '20200101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000
- use_hash 힌트만 사용했으므로 Build Input을 옵티마이저가 선택
- 일반적으로 카디널리티가 작은 테이블 선택
1
2
3
4
5
select /*+ ordered use_hash(c) */ ...
from 사원 e, 고객 c
select /*+ leading(e) use_hash(c) */ ...
from 사원 e, 고객 c
- Build Input 지정. 사원 테이블을 첫 번째 테이블로 삼아서 해시 맵 생성
1
2
select /*+ leading(e) use_hash(c) swap_join_inputs(c) */ ...
from 사원 e, 고객 c
- swap_join_inputs 힌트는 해시 조인의 Build Input과 Probe Input을 서로 바꿈
- 강제로 c 테이블을 Build Input으로 지정
세 개 이상 테이블 해시 조인
조인 대상 테이블이 3개 이상이면 조건 절에 따라 양상이 두 가지로 나뉨
1
2
3
4
select *
from A, B, C
where A.key = B.key
and B.key = C.key
경로 1 : A $\leftrightarrow$ B $\leftrightarrow$ C
1
2
3
4
select *
from A, B, C
where A.key = B.key
and A.key = C.key
경로 2 : A $\leftrightarrow$ B, A $\leftrightarrow$ C
하지만 경로 2는 B $\leftrightarrow$ A $\leftrightarrow$ C 로 표현할 수 있으므로 결국은 똑같음.
1
2
3
4
select /*+ leading(T1, T2, T3) use_hash(T2) use_hash(T3) */ *
from T1, T2, T3
where T1.key = T2.key
and T2.key = T3.key
leading 힌트 첫 번째 파라미터로 지정한 테이블은 무조건 Build Input으로 선택됨
T1와 T2가 조인할 때 항상 T1이 Build Input으로 선택됨.
다음과 같은 두 가지 패턴이 가능함.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
< 패턴 1 >
Execution Plan
----------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 HASH JOIN
2 1 HASH JOIN
3 2 TABLE ACCESS (FULL) OF 'T1' (TABLE)
4 2 TABLE ACCESS (FULL) OF 'T2' (TABLE)
5 1 TABLE ACCESS (FULL) OF 'T3' (TABLE)
< 패턴 2 >
Execution Plan
----------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 HASH JOIN
2 1 TABLE ACCESS (FULL) OF 'T3' (TABLE)
3 1 HASH JOIN
4 3 TABLE ACCESS (FULL) OF 'T1' (TABLE)
5 3 TABLE ACCESS (FULL) OF 'T2' (TABLE)
T2를 Build Input으로 선택하고 싶으면
1
select /*+ leading(T1, T2, T3) swap_join_inputs(T2) */ *
swap_join_inputs 힌트 사용하면 아래와 같이 실행계획이 바뀜.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
< 패턴 1 >
Execution Plan
----------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 HASH JOIN
2 1 HASH JOIN
3 2 TABLE ACCESS (FULL) OF 'T2' (TABLE)
4 2 TABLE ACCESS (FULL) OF 'T1' (TABLE)
5 1 TABLE ACCESS (FULL) OF 'T3' (TABLE)
< 패턴 2 >
Execution Plan
----------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 HASH JOIN
2 1 TABLE ACCESS (FULL) OF 'T3' (TABLE)
3 1 HASH JOIN
4 3 TABLE ACCESS (FULL) OF 'T2' (TABLE)
5 3 TABLE ACCESS (FULL) OF 'T1' (TABLE)
Built Input으로 선택하고 싶은 테이블이 조인된 결과 집합이어서 swap_join_inputs 힌트로 지정하기 어려울 땐, 반대쪽 Probe Input에 no_swap_join_inputs를 걸어주면 된다.
조인 메소드 선택 기준
해시 조인이 빠르고, 인덱스 설계도 안 해도 돼서 굉장히 좋아보인다.
하지만 수행빈도가 높은 쿼리에 대해서는 조심해야 한다.
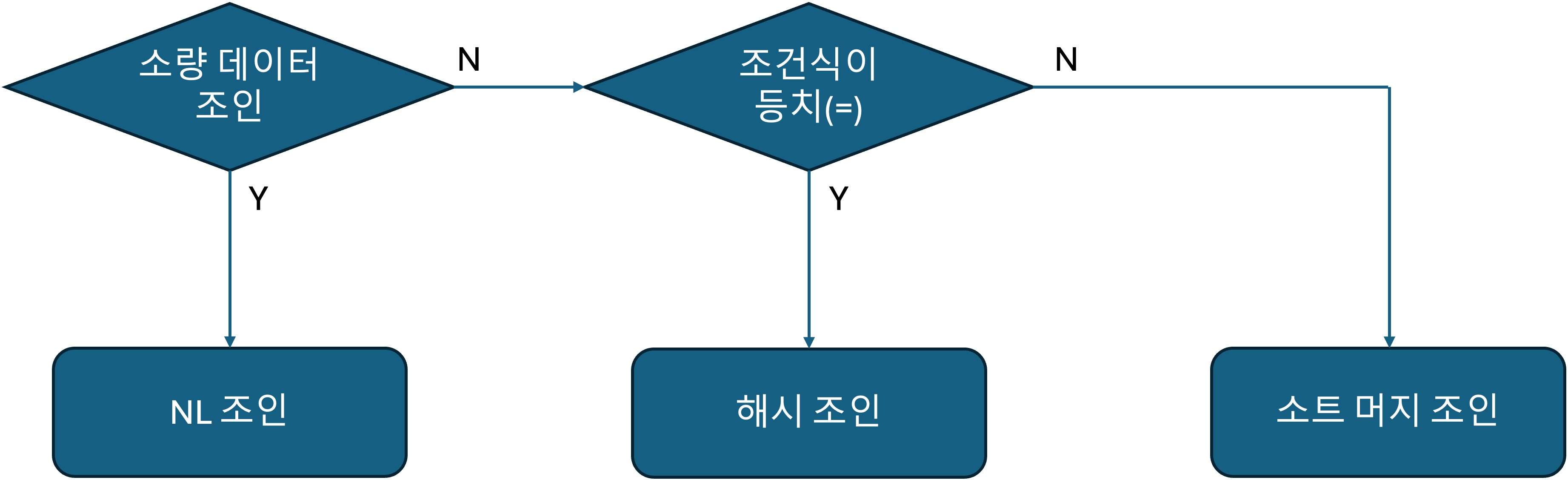
- 소량 데이터 조인할 때 $\rightarrow$ NL 조인
- 대량 데이터 조인할 때 $\rightarrow$ 해시 조인
- 대량 데이터 조인인데, 조인 조건식이 등치 조건이 아닐 때 (or 조인 조건식이 없는 카테시안 곱일 때) $\rightarrow$ 소트 머지 조인
NL 조인 기준으로 ‘최적화 했는데도’ 랜덤 액세스가 많아 만족할만한 성능을 낼 수 없다면 “대량 데이터 조인”
수행 빈도가 매우 높은 쿼리에 대해서는 다음과 같은 선택 기준도 성립
- (최적화된) NL 조인과 해시 조인 성능이 같으면 $\rightarrow$ NL 조인
- 해시 조인이 약간 더 빠를 때 $\rightarrow$ NL 조인
- NL 조인보다 해시 조인이 매우 빠를 때 $\rightarrow$ 해시 조인
3번 경우는 아마 대량 조인일 것이므로, 대량 데이터 조인할 때 해시 조인 쓰라는 말과 같음.
1번, 2번 경우는 아마 소량 조인일 것이므로, 소량 데이터 조인할 때는 NL 조인 쓰라는 말과 같음.
조인 메소드를 선택할 때 NL 조인을 가장 먼저 고려해야 함.
NL 조인에 사용하는 인덱스는 영구적으로 유지하면서 다양한 쿼리를 위해 공유 및 재사용하는 자료구조.
해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 곧바로 소멸하는 자료구조.
- 같은 쿼리를 100개의 프로세스가 동시에 수행하면 해시 테이블도 100개가 만들어짐
수행시간이 짧으면서 수행빈도가 매우 높은 쿼리(OLTP성 쿼리)를 해시 조인으로 처리하면 CPU와 메모리 비용이 증가함.
해시 맵을 만드는 과정에 래치 경합도 생김.
따라서, 해시 조인은 아래 세 가지 조건을 만족하는 쿼리에 주로 사용함
- 수행 빈도가 낮고
- 쿼리 수행 시간이 오래 걸리는
- 대량 데이터 조인할 때
Subquery join
서브쿼리 변환이 필요한 이유
옵티마이저는 사용자의 쿼리를 의미적으로 동일하면서 더 나은 성능이 기대되는 형태로 쿼리 변환(Query Transformation)을 함.
서브쿼리 : 하나의 SQL문 안에 괄호로 묶은 별도의 쿼리 블록
- Inline View : FROM 절에 사용한 서브쿼리
- Nested Subquery : 결과집합을 한정하기 위해 WHERE 절에 사용한 서브쿼리
- 서브쿼리가 메인쿼리 칼럼을 참조하면 Correlated Subquery
- Scalar Subquery : 한 레코드당 정확히 하나의 값을 반환하는 서브쿼리.
- 주로 SELECT-LIST에서 사용하지만, 칼럼이 올 수 있는 대부분의 위치에 사용 가능.
이 서브쿼리를 참조하는 메인 쿼리도 하나의 쿼리 블록이며, 옵티마이저는 쿼리 블록 단위로 최적화를 수행.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
-- < 원본 쿼리 >
select c.고객번호, c.고객명
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and exists (
select 'x'
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'mm') )
-- < 쿼리 블록 1 >
select c.고객번호, c.고객명
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
-- < 쿼리 블록 2 >
select 'x'
from 거래
where 고객번호 = :cust_no -- 메인쿼리를 참조하는 조건절은 변수로 처리
and 거래일시 >= trunc(sysdate, 'mm')
- 원본 쿼리를 변환하지 않고 그대로 수행하면, 메인 쿼리와 EXISTS 서브쿼리를 각각 최적화함
- 이렇게 서브쿼리별로 최적화한 쿼리가 전체적으로도 최적화됐다고 할 수 없음
- 옵티마이저가 쿼리 전체 관점에서 쿼리를 이해하려면 서브쿼리를 풀어내야 함
서브쿼리와 조인
메인쿼리와 서브쿼리는 종속적이고 계층 관계가 존재.
서브쿼리는 메인쿼리에 종속되므로 단독으로 실행될 수 없음. 메인쿼리 건수만큼 값을 받아 반복적으로 필터링하는 방식으로 실행해야 함.
Filter
필터는 쿼리에서 특정 조건에 맞는 데이터만 선택하는 메커니즘.
주로 WHERE 절이나 서브쿼리에서 사용됨.
1
2
3
4
5
6
7
8
select c.고객번호, c.고객명
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and exists (
select /*+ no_unnest */ 'x'
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'mm') )
- 서브쿼리를 필터 방식으로 처리하려고 no_unnest 힌트 사용
1
2
3
4
5
6
7
Execution Plan
------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=289 Card=1 Bytes=39)
1 0 FILTER
2 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=4 Card=190 ...)
3 2 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=2 Card=190)
4 1 INDEX (RANGE SCAN) OF '거래_X01' (INDEX) (Cost=3 Card=4K Bytes=92K)
필터는 기본적으로 NL 조인과 처리 루틴이 같음
- FILTER 부분을 NESTED LOOPS로 치환하고 해석하면 됨
- NL 조인처럼 부분 범위 처리도 가능
필터와 Nested Loops의 관계
- NL 조인 : 두 테이블을 결합하여 결과 집합 생성
- 서브쿼리 형태의 필터 : 조건을 만족하는 행만 선택
1
2
3
4
5
6
7
8
9
10
11
-- FILTER pseudocode
begin
for outer in (select 고객번호, 고객명 from 고객 where ... )
loop
for inner in (select 'x' from 거래 where 고객번호 = outer.고객번호 and ... )
loop
dbms_output.put_line(outer.고객번호 || ',' || outer.고객명);
exit;
end loop;
end loop;
end;
- 조건을 만족하는 첫 번째 행을 찾으면 즉시 서브쿼리 실행을 중단하고 TRUE 반환
- 조인에 성공하면 inner loop exit
- 필터는 캐싱기능을 갖음
- 서브쿼리 입력 값에 따른 서브쿼리 결과(TRUE/FALSE)를 PGA 메모리에 저장
- TRUE: 서브쿼리 조건이 충족됨 (해당 행이 메인 쿼리 결과에 포함됨)
- FALSE: 서브쿼리 조건이 충족되지 않음 (해당 행이 메인 쿼리 결과에서 제외됨)
- 이후 같은 값으로 서브쿼리 실행 시 캐시된 결과 사용
- 캐시에서 true/false 여부를 확인할 수 있다면 서브쿼리를 수행하지 않아도 됨.
- 서브쿼리 입력 값에 따른 서브쿼리 결과(TRUE/FALSE)를 PGA 메모리에 저장
- 캐싱은 쿼리 단위로 이루어짐
- 쿼리를 시작할 때 PGA 메모리에 공간을 할당하고, 쿼리를 수행하면서 공간을 채워나가고, 쿼리를 마치면 반환
- 필터 서브쿼리는 일반 NL 조인과 달리 메인쿼리에 종속되므로, 조인 순서가 고정됨
- 항상 메인쿼리가 드라이빙 집합. 항상 메인쿼리가 먼저 실행되고(드라이빙), 서브쿼리는 종속적으로 실행됨
서브쿼리 Unnesting
서브쿼리 unnesting은 메인과 서브쿼리 간의 계층구조를 풀어, 서로 같은 레벨로 만들어 줌. Flattening이라고도 부름.
- 일반적으로 EXISTS 서브쿼리는 메인 쿼리의 각 행에 대해 서브쿼리가 실행됨
- unnest 힌트를 사용하면 서브쿼리가 조인으로 변환됨
Unnesting을 하고 나면 일반 조인문처럼 다양한 최적화 기법을 사용할 수 있음.
1
2
3
4
5
6
7
8
select c.고객번호, c.고객명
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and exists (
select /*+ unnest nl_sj */ 'x'
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'mm') )
1
2
3
4
5
6
7
Execution Plan
------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=384 Card=190 Bytes=11K)
1 0 NESTED LOOPS (SEMI) (Cost=384 Card=190 Bytes=11K)
2 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=4 Card=190 ...)
3 2 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=2 Card=190)
4 1 INDEX (RANGE SCAN) OF '거래_X01' (INDEX) (Cost=2 Card=427K Bytes=9M)
- unnest와 nl_sj 힌트로 NL 세미조인 방식으로 실행됨
NL semi join
- 기본적으로 NL 조인과 같은 프로세스
- 조인에 성공하는 순간 멈추고, 메인 쿼리의 다음 로우를 처리함 (필터랑 동일)
필터 방식은 항상 메인쿼리가 드라이빙 집합이지만, Unnesting 된 서브쿼리를 메인 쿼리 집합보다 먼저 처리될 수 있음.
1
2
3
4
5
6
7
8
select /*+ leading(거래@subq) use_nl(c) */ c.고객번호, c.고객명
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and exists (
select /*+ qb_name(subq) unnest */ 'x'
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'mm') )
- leading(거래@subq) : 서브쿼리(qb_name으로 subq라고 명명)의 ‘거래’ 테이블을 드라이빙 테이블로 사용
1
2
3
4
5
6
7
8
9
10
Execution Plan
------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=253K Card=190 Bytes=11K)
1 0 NESTED LOOPS
2 1 NESTED LOOPS (Cost=253K Card=190 Bytes=11K)
3 2 SORT (UNIQUE) (Cost=2K Card=427K Bytes=9M)
4 3 TABLE ACCESS (BY INDEX ROWID) OF '거래' (TABLE) (Cost=2K ...)
5 4 INDEX (RANGE SCAN) OF '거래_X02' (INDEX) (Cost=988 Card=427K)
6 2 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=1 Card=190)
7 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=3 Card=1 ...)
실행계획 순서
거래 테이블에서 거래일시 >= trunc(sysdate, ‘mm’) 조건으로 거래_X02 인덱스를 사용해 데이터 접근 (5번 라인)
거래 테이블에 접근 (4번 라인)
중복 제거를 위한 SORT UNIQUE 수행 (3번 라인) - 여기서 고객번호 기준으로 중복 제거
고객_X01 인덱스에 접근하여 가입일시 >= trunc(add_months(sysdate, -1), ‘mm’) 조건과 매칭되는 고객 찾기 (6번 라인)
고객 테이블에 접근하여 최종 데이터 검색 (7번 라인)
Sort Unique의 필요성
- 서브쿼리를 조인으로 변환할 때 데이터가 중복됨
- 원래는 EXISTS문에서는 조건을 만족하는 행이 하나라도 있으면 TRUE 반환
- 조인으로 변환했을 때, 조건을 만족하는 거래 테이블의 행이 여러 개 있을 경우, 여러 번 출력될 수 있음
- 이를 방지하기 위해 거래 테이블의 고객번호에 대해 SORT UNIQUE 작업 수행
서브쿼리 Pushing
Unnesting 되지 않은 서브쿼리는 항상 필터 방식으로 처리됨. 대개 실행계획 가장 마지막에 처리됨.
1
2
3
4
5
6
7
8
select /*+ leading(p) use_nl(t) */ count(distinct p.상품번호), sum(t.주문금액)
from 상품 p, 주문 t
where p.상품번호 = t.상품번호
and p.등록일시 >= trunc(add_months(sysdate, -3), 'mm')
and t.주문일시 >= trunc(sysdate - 7)
and exists (select 'x' from 상품분류
where 상품분류코드 = p.상품분류코드
and 상위분류코드 = 'AK')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------- -------- -------- -------- ------
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.484 3.493 650 38103 0 1
------- ------ -------- ------------- -------- -------- -------- ------
Total 4 0.484 3.493 650 38103 0 1
Rows Row Source Operation
------- ------------------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=38103 pr=650 pw=0 time=3493306 us)
3000 FILTER (cr=38103 pr=650 pw=0 time=3486253 us)
60000 NESTED LOOPS (cr=38097 pr=650 pw=0 time=3602032 us)
1000 TABLE ACCESS FULL 상품 (cr=95 pr=0 pw=0 time=342023 us)
60000 TABLE ACCESS BY INDEX ROWID 주문 (cr=38002 pr=650 pw=0 time=...)
60000 INDEX RANGE SCAN 주문_PK (cr=2002 pr=90 pw=0 time=964606 us)
1 TABLE ACCESS BY INDEX ROWID 상품분류 (cr=6 pr=0 pw=0 time=78 us)
3 INDEX UNIQUE SCAN 상품분류_PK (cr=3 pr=0 pw=0 time=36 us)
- 상품으로부터 주문 테이블로 조인 액세스 1,000 번
- 조인에 성공한 주문 데이터가 60,000 개
- 조인 과정에 38097 개의 블록 읽음
- 60,000개의 조인 결과집합은 서브쿼리 필터링 하고 나면 3,000개로 감소
- 총 읽은 블록 수는 38,103 개
- 대부분의 I/O가 조인 과정에서 발생했음
- 서브쿼리 필터링을 먼저 처리하고 나서 조인 단계로 넘어가는 로우 수를 줄일 수 있으면 성능 향상
1
2
3
4
5
6
7
8
select /*+ leading(p) use_nl(t) */ count(distinct p.상품번호), sum(t.주문금액)
from 상품 p, 주문 t
where p.상품번호 = t.상품번호
and p.등록일시 >= trunc(add_months(sysdate, -3), 'mm')
and t.주문일시 >= trunc(sysdate - 7)
and exists (select /*+ NO_UNNEST PUSH_SUBQ */ 'x' from 상품분류
where 상품분류코드 = p.상품분류코드
and 상위분류코드 = 'AK')
- 서브쿼리 필터링을 먼저 처리하게 하려고 push_subq 힌트 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------- -------- -------- -------- ------
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.125 0.129 0 1903 0 1
------- ------ -------- ------------- -------- -------- -------- ------
Total 4 0.125 0.129 0 1903 0 1
Rows Row Source Operation
------- ------------------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=1903 pr=0 pw=0 time=128934 us)
3000 NESTED LOOPS (cr=1903 pr=0 pw=0 time=153252 us)
150 TABLE ACCESS FULL 상품 (cr=101 pr=0 pw=0 time=18230 us)
1 TABLE ACCESS BY INDEX ROWID 상품분류 (cr=6 pr=0 pw=0 time=135 us)
3 INDEX UNIQUE SCAN 상품분류_PK (cr=3 pr=0 pw=0 time=63 us)
3000 TABLE ACCESS BY INDEX ROWID 주문 (cr=1802 pr=0 pw=0 time=100092 us)
3000 INDEX RANGE SCAN 주문_PK (cr=302 pr=0 pw=0 time=41733 us)
- 서브쿼리 필터링한 결과가 150건 $\rightarrow$ 조인 횟수도 150번
- 주문 데이터 3,000개 읽음
- 총 읽은 블록 수 1,903 으로 감소
Pushing 서브쿼리는 서브쿼리 필터링을 가능한 한 앞 단계에서 처리하도록 강제하는 기능.
이 기능은 Unnesting 되지 않은 서브쿼리에만 작동.
Unnesting이 되면 push_subq 힌트가 먹지 않음. 항상 no_unnest 힌트와 함께 사용.
서브쿼리 필터링을 가능한 한 나중에 처리하고 으면 no_unnnest, no_push_subq 힌트 사용.
뷰와 조인
최적화 단위가 쿼리 블록이므로, 옵티마이저가 View 쿼리를 변환하지 않으면 뷰 쿼리 블록을 독립적으로 최적화.
1
2
3
4
5
6
7
8
9
select c.고객번호, c.고객명, t.평균거래, t.최소거래, t.최대거래
from 고객 c
,(select 고객번호, avg(거래금액) 평균거래
, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm') -- 당월 발생한 거래
group by 고객번호) t
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm') -- 전월 이후 가입 고객
and t.고객번호 = c.고객번호
1
2
3
4
5
6
7
8
9
10
11
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1M Card=1K Bytes=112K)
1 0 NESTED LOOPS
2 1 NESTED LOOPS (Cost=1M Card=1K Bytes=112K)
3 2 VIEW (Cost=2K Card=427K Bytes=21M)
4 3 HASH (GROUP BY) (Cost=2K Card=427K Bytes=14M)
5 4 TABLE ACCESS (BY INDEX ROWID) OF '거래' (TABLE) (Cost=2K ...)
6 5 INDEX (RANGE SCAN) OF '거래_X01' (INDEX) (Cost=988 Card=427K)
7 2 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=1 Card=190)
8 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=3 Card=1 ...)
- 고객 테이블에서 ‘전월 이후 가입한 고객’을 필터링 하는 조건이 인라인 뷰 바깥에 있음.
- 인라인 뷰 안에서는 당월에 거래한 모든 고객의 거래 데이터를 읽어야 함
1
2
3
4
5
6
7
8
9
select c.고객번호, c.고객명, t.평균거래, t.최소거래, t.최대거래
from 고객 c
,(select /*+ merge */ 고객번호, avg(거래금액) 평균거래
, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
group by 고객번호) t
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and t.고객번호 = c.고객번호
- merge 힌트로 뷰를 메인 쿼리와 Merging (하기 싫으면 no_merge)
1
2
3
4
5
6
7
8
9
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=4 Card=1 Bytes=27)
1 0 HASH (GROUP BY) (Cost=4 Card=1 Bytes=27)
2 1 NESTED LOOPS (Cost=3 Card=5 Bytes=135)
3 2 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=2 Card=1 ...)
4 3 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=1 Card=1)
5 2 TABLE ACCESS (BY INDEX ROWID) OF '거래' (TABLE) (Cost=1 Card=5 ...)
6 5 INDEX (RANGE SCAN) OF '거래_X02' (INDEX) (Cost=0 Card=5)
- 가장 먼저 액세스하는 고객_X01 인덱스는 가입일시가 선두 칼럼이겠지. range scan 했잖아.
거래_X02 인덱스는 [고객번호, 거래일시] 순으로 구성되어 있는 게 최적
인덱스를 이용해 전월 이후 가입한 고객만 읽고
- 거래 테이블과 조인할 때는 해당 고객들에 대한 당월 거래만 읽음
- 거래 테이블을 [고객번호, 거래일시] 순으로 구성된 인덱스를 이용해 NL 방식으로 조인하기 때문에 가능
1
2
3
4
5
6
7
select c.고객번호, c.고객명
, avg(t.거래금액) 평균거래, min(t.거래금액) 최소거래, max(t.거래금액) 최대거래
from 고객 c, 거래 t
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and t.고객번호 = c.고객번호
and t.거래일시 >= trunc(sysdate, 'mm')
group by c.고객번호, c.고객명
- 사실상 쿼리가 이렇게 변한 거
- 단점은, 조인에 성공한 전체 집합을 group by 하고나서 데이터를 출력할 수 있음 (부분범위 처리가 불가능)
- 만약 전월 이후 가입한 고객이 많고, 당월 거래도 많으면, 부분범위 처리가 불가해서 NL 조인이 좋지 않음
1
2
3
4
5
6
7
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=8 Card=1 Bytes=27)
1 0 HASH (GROUP BY) (Cost=8 Card=1 Bytes=27)
2 1 HASH JOIN (Cost=7 Card=5 Bytes=135)
3 2 TABLE ACCESS (FULL) OF '고객' (TABLE) (Cost=3 Card=1 Bytes=20)
4 2 TABLE ACCESS (FULL) OF '거래' (TABLE) (Cost=3 Card=14 Bytes=98)
- hash join 사용하면 이런 형태
조인 조건 Pushdown
메인 쿼리를 실행하면서 조인 조건절 값을 건건이 뷰 안으로 밀어 넣는 기능.
1
2
3
4
5
6
7
8
9
10
select c.고객번호, c.고객명, t.평균거래, t.최소거래, t.최대거래
from 고객 c
,(select /*+ no_merge push_pred */
고객번호, avg(거래금액) 평균거래
, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
group by 고객번호) t
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and t.고객번호 = c.고객번호
- push_pred는 옵티마이저가 뷰를 머징하면 힌트가 작동하지 않음. no_merge 와 같이 사용.
1
2
3
4
5
6
7
8
9
10
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=4 Card=1 Bytes=61)
1 0 NESTED LOOPS (Cost=4 Card=1 Bytes=61)
2 1 TABLE ACCESS (BY INDEX ROWID BATCHED) OF '고객' (TABLE) (Cost=2 ...)
3 2 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=1 Card=1)
4 1 VIEW PUSHED PREDICATE (Cost=2 Card=1 Bytes=41)
5 4 SORT (GROUP BY) (Cost=2 Card=1 Bytes=7)
6 5 TABLE ACCESS (BY INDEX ROWID BATCHED) OF '거래' (TABLE) (Cost=2 ...)
7 6 INDEX (RANGE SCAN) OF '거래_X02' (INDEX) (Cost=1 Card=5)
- 전월 이후 가입한 고객을 대상으로 건건이 당월 거래 데이터만 읽어서 조인하고 Group By
- 중간에 멈출 수도 있음. 부분범위 처리 가능.
- 뷰를 독립적으로 실행할 때처럼 당월 거래를 모두 읽지 않아도 되고, 뷰를 머징할 때처럼 조인에 성공한 전체 집합을 group by 하지 않아도 됨
1
2
3
4
5
6
7
8
9
select c.고객번호, c.고객명, t.평균거래, t.최소거래, t.최대거래
from 고객 c
,(select 고객번호, avg(거래금액) 평균거래
, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
and 고객번호 = c.고객번호
group by 고객번호) t
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
- 위 쿼리는 오류가 나긴 하지만, 옵티마이저가 이런 식으로 쿼리를 변환한 거
스칼라 서브쿼리 조인
GET_DNAME 함수 생성
1
2
3
4
5
6
7
8
9
10
11
create or replace function GET_DNAME(p_deptno number) return varchar2
is
l_dname dept.dname%TYPE;
begin
select dname into l_dname from dept where deptno = p_deptno;
return l_dname ;
exception
when others then
return null;
end;
/
이 함수를 사용하는 쿼리를 실행하면
1
2
3
4
select empno, ename, sal, hiredate,
GET_DATE(e.deptno) as dname
from emp e
where sal >= 2000
- 함수 안에 있는 select 쿼리를 메인쿼리 건수만큼 재귀적으로 반복 실행
1
2
3
4
select empno, ename, sal, hiredate,
(select d.dname from dept d where d.deptno = e.deptno) as dname
from emp e
where sal >= 2000
- 이 스칼라 서브쿼리는 메인쿼리 레코드마다 정확히 하나의 값만 반환
- 메인쿼리 건수만큼 dept 테이블을 반복해서 읽긴 하지만, GET_DNAME 함수처럼 재귀적으로 실행되는 구조는 아님
- 컨텍스트 스위칭 없이 메인쿼리와 서브쿼리를 같이 실행
- 이렇게 실행하면 아래 outer join을 사용한 쿼리처럼 NL 조인 방식으로 실행됨.
1
2
3
4
select /*+ ordered use_nl(d) */ e.empno, e.ename, e.sal, e.hiredate, d.dname
from emp e, dept d
where d.deptno(+) = e.deptno
and e.sal >= 2000
- dept와 조인에 실패하는 emp 레코드는 DNAME에 NULL을 출력하는 것도 같음
- 차이점은, 스칼라 서브쿼리는 처리 과정에서 캐싱 작용이 일어남
스칼라 서브쿼리 캐싱
스칼라 서브쿼리로 조인하면, 오라클은 조인 횟수를 최소화하려고 입력 값과 출력 값을 내부 Query Execution Cache에 저장.
조인할 때마다 캐시에서 입력값을 찾아보고, 찾으면 저장된 출력값 반환.
캐시에서 찾지 못할 때만 조인을 수행하고, 결과는 캐시에 저장.
스칼라 서브쿼리의 입력값은 그 안에서 참조하는 메인 쿼리의 칼럼 값.
1
2
3
4
5
6
select empno, ename, sal, hiredate,
( select d.dname -- 출력값 : d.dname
from dept d
where d.deptno = e.deptno ) -- 입력값 : e.deptno
from employee e
where sal >= 2000
스칼라 서브쿼리 캐싱은 필터 서브쿼리 캐싱과 같은 기능.
메인쿼리 집합이 아무리 커도 조인할 데이터를 대부분 캐시에서 찾으면 조인 수행횟수를 최소화할 수 있어서, 성능향상에 도움이 됨.
캐싱은 쿼리 단위로 이루어짐.
- 쿼리를 시작할 때 PGA 메모리에 공간을 할당하고, 쿼리를 수행하면서 공간을 채워나가고, 쿼리를 마치면 공간 반환.
이 캐싱을 사용한 튜닝도 가능.
SELECT-LIST에 사용한 함수는 메인쿼리 결과 건수만큼 반복 수행되는데,
1
2
3
4
select empno, ename, sal, hiredate,
(select GET_DNAME(e.deptno) from dual) dname
from emp e
where sal >= 2000
이렇게 스칼라 서브쿼리를 덧씌우면 호출 횟수를 최소화할 수 있음.
함수에 내장된 SELECT 쿼리도 그만큼 덜 수행됨
스칼라 서브쿼리 캐싱 부작용
캐시 공간은 메모리 공간이 작음.
스칼라 서브쿼리 캐싱 효과는 입력 값의 종류가 소수여서 해시 충돌 가능성이 작을 때 효과가 있다.
아니면 캐시를 매번 확인하는 비용 때문에 오히려 성능이 나빠지고 CPU 사용율만 높아짐. 메모리도 더 쓰고.
select 거래번호, 고객번호, 영업조직ID, 거래구분코드,
(select 거래구분명 from 거래구분 where 거래구분코드 = t.거래구분코드) 거래구분명
from 거래 t
where 거래일자 >= to_char(add_months(sysdate, -3), 'yyyymmdd') -- 50,000건
- 고객이 100만 명인 고객 테이블과 조인하는 경우
- 캐시에 담을 수 없을 만큼 고객번호가 많음
- 메인쿼리에서 50,000개 거래를 읽는 동안 캐시를 매번 탐색하지만, 대부분 데이터 찾지 못하고 조인 수행
함수 호출 횟수를 줄이기 위해 스칼라 서브쿼리를 덧씌우는 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
select 매도회원번호
, 매수회원번호
, 매도투자자구분코드
, 매수투자자구분코드
, 체결유형코드
, 매도계좌번호, (select acnt_nm(매도계좌번호) from dual) 매도계좌명
, 매수계좌번호, (select acnt_nm(매수계좌번호) from dual) 매수계좌명
, 체결시각
, 체결수량
, 체결가
, 체결수량 * 체결가 체결금액
from 체결
where 종목코드 = :종목코드
and 체결일자 = :체결일자
and 체결시각 between sysdate-10/24/60 and sysdate
- 체결 테이블에 입력된 매도계좌번호, 매수계좌번호가 무수히 많다면 스칼라 서브쿼리 캐싱 효과를 기대할 수 없음
- 오히려 성능 저하
메인 쿼리 집합이 매우 작을 때도 스칼라 서브쿼리 캐싱이 성능에 도움을 주지 못함.
- 스칼라 서브쿼리 캐싱은 쿼리 단위.
- 메인쿼리 집합이 클 수록 재사용성이 높아 효과도 큼
- 메인쿼리 집합이 작으면 캐시 재사용성이 낮음
1
2
3
4
5
select 계좌번호, 계좌명, 고객번호, 개설일자, 계좌종류구분코드, 은행계설여부, 은행연계여부
,(select brch_nm(관리지점코드) from dual) 관리지점명
,(select brch_nm(개설지점코드) from dual) 개설지점명
from 계좌
where 고객번호 = :고객번호
- 고객당 계좌가 많지 않음 (보통은 한 개)
- 쓰지도 않은 캐시를 할당해서 값을 채웠다가 바로 버림
두 개 이상의 값 반환
1
2
3
4
5
6
7
select c.고객번호, c.고객명
,(select round(avg(거래금액), 2) 평균거래금액
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
and 고객번호 = c.고객번호)
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
1
2
3
4
5
6
7
8
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=7 Card=4 Bytes=80)
1 0 SORT (AGGREGATE) (Card=1 Bytes=7)
2 1 TABLE ACCESS (BY INDEX ROWID BATCHED) OF '거래' (TABLE) (Cost=2 ...)
3 2 INDEX (RANGE SCAN) OF '거래_X02' (INDEX) (Cost=1 Card=5)
4 0 TABLE ACCESS (FULL) OF '고객' (TABLE) (Cost=3 Card=4 Bytes=80)
5 4 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=1 Card=1)
- 메인 쿼리가 실행계획 아래쪽에 있고, 스칼라 서브쿼리는 위쪽에 있음
스칼라 서브쿼리는 NL 조인과 프로세싱 과정이 같고, 부분 범위 처리도 가능. 캐싱도 가능.
하지만 스칼라 서브쿼리는 두 개 이상의 값을 반환할 수 없음
1
2
3
4
5
6
7
select c.고객번호, c.고객명
,(select avg(거래금액), min(거래금액), max(거래금액)
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
and 고객번호 = c.고객번호)
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
- 이렇게 쿼리를 쓸 수가 없음
1
2
3
4
5
6
7
8
9
select c.고객번호, c.고객명
,(select avg(거래금액) from 거래
where 거래일시 >= trunc(sysdate, 'mm') and 고객번호 = c.고객번호)
,(select min(거래금액) from 거래
where 거래일시 >= trunc(sysdate, 'mm') and 고객번호 = c.고객번호)
,(select max(거래금액) from 거래
where 거래일시 >= trunc(sysdate, 'mm') and 고객번호 = c.고객번호)
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
- 그렇다고 이렇게 하나씩 읽으면 반복해서 읽어야 해서 비효율적
해결책 중 하나는, 구하는 값들을 문자열로 모두 결합하고, 바깥쪽 액세스 쿼리에서 substr 함수로 다시 분리하는 것
1
2
3
4
5
6
7
8
9
10
11
12
13
select 고객번호, 고객명
, to_number(substr(거래금액, 1, 10)) 평균거래금액
, to_number(substr(거래금액, 11, 10)) 최소거래금액
, to_number(substr(거래금액, 21)) 최대거래금액
from (
select c.고객번호, c.고객명
,(select lpad(avg(거래금액), 10) || lpad(min(거래금액), 10) || max(거래금액)
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
and 고객번호 = c.고객번호) 거래금액
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
)
오브젝트 TYPE을 사용하는 방법도 있음
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
create or replace type 거래금액_T as object
( 평균거래금액 number, 최소거래금액 number, 최대거래금액 number )
/
select 고객번호, 고객명
, 거래.금액.평균거래금액, 거래.금액.최소거래금액, 거래.금액.최대거래금액
from (
select c.고객번호, c.고객명
,(select 거래금액_T( avg(거래금액), min(거래금액), max(거래금액) ) 금액
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
and 고객번호 = c.고객번호) 거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
and 고객번호 = c.고객번호) 거래
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
)
두 개 이상의 값을 반환하고 싶을 때, 스칼라 서브쿼리 말고 인라인 뷰 사용하면 편함
1
2
3
4
5
6
7
8
9
select c.고객번호, c.고객명, t.평균거래, t.최소거래, t.최대거래
from 고객 c
,(select 고객번호, avg(거래금액) 평균거래
, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
group by 고객번호) t
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and t.고객번호(+) = c.고객번호
1
2
3
4
5
6
7
8
9
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=4 Card=1 Bytes=27)
1 0 HASH (GROUP BY) (Cost=4 Card=1 Bytes=27)
2 1 NESTED LOOPS (OUTER) (Cost=3 Card=5 Bytes=135)
3 2 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=2 Card=1 ...)
4 3 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=1 Card=1)
5 2 TABLE ACCESS (BY INDEX ROWID) OF '거래' (TABLE) (Cost=1 Card=5 ...)
6 5 INDEX (RANGE SCAN) OF '거래_X02' (INDEX) (Cost=0 Card=5)
- 뷰를 사용하면 뷰가 머징되지 않았을 때 당월 거래 전체를 읽어야 하거나
- 뷰가 머징될 때 group by 때문에 부분범위 처리가 안 됨
- 조인 조건 pushdown 기능도 있어서 오히려 좋아
스칼라 서브쿼리 Unnesting
스칼라 서브쿼리도 NL 방식으로 조인하므로, 캐싱 효과가 크지 않으면 랜덤 I/O 부하가 있음.
따라서, 다른 조인 방식을 선택하기 위해 스칼라 서브쿼리를 일반 조인문으로 변환하고 싶을 때가 있음.
병렬(Parallel) 쿼리에선 될 수 있으면 스칼라 서브쿼리를 사용하지 않아야 함. 대량 데이터를 처리하는 병렬 쿼리는 해시 조인으로 처리하는 게 효과적.
스칼라 서브쿼리 Unnesting 기능이 있어서 사용자가 직접 쿼리를 변환해야 할 필요는 없음.
1
2
3
4
5
6
7
select c.고객번호, c.고객명
,(select /*+ unnest */ round(avg(거래금액), 2) 평균거래금액
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
and 고객번호 = c.고객번호)
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
1
2
3
4
5
6
7
8
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=7 Card=4 Bytes=184)
1 0 HASH JOIN (OUTER) (Cost=7 Card=4 Bytes=184)
2 1 TABLE ACCESS (FULL) OF '고객' (TABLE) (Cost=3 Card=4 Bytes=80)
3 1 VIEW OF 'SYS.VW_SSQ_1' (VIEW) (Cost=4 Card=3 Bytes=78)
4 3 HASH (GROUP BY) (Cost=4 Card=3 Bytes=21)
5 4 TABLE ACCESS (FULL) OF '거래' (TABLE) (Cost=3 Card=14 Bytes=98)
- 스칼라 서브쿼리인데도 NL 조인이 아니라 해시 조인으로 실행됨
1
2
3
4
5
6
7
Execution Plan
------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=7 Card=15 Bytes=405)
1 0 HASH (GROUP BY) (Cost=7 Card=15 Bytes=405)
2 1 HASH JOIN (OUTER) (Cost=6 Card=15 Bytes=405)
3 2 TABLE ACCESS (FULL) OF '고객' (TABLE) (Cost=3 Card=4 Bytes=80)
4 2 TABLE ACCESS (FULL) OF '거래' (TABLE) (Cost=3 Card=14 Bytes=98)
- unnest와 merge 힌트 사용함
출처
친절한 SQL 튜닝
Memory architecture. Oracle Help Center. https://docs.oracle.com/en/database/oracle/oracle-database/19/cncpt/memory-architecture.html#GUID-1CB2BA23-4386-46DA-9146-5FE0E4599AC6