[DB] 인덱스
인덱스 구조 및 탐색
| 이름 | 키 | 시력 |
|---|---|---|
| 김철수 | 175cm | 1.2 |
| 이영희 | 165cm | 0.4 |
| … | … | |
| 박민준 | 180cm | 0.7 |
| 정수진 | 160cm | 1.0 |
| 최현우 | 178cm | 1.5 |
인덱스 튜닝은 결국 두 가지로 나뉜다
- 인덱스 스캔 효율화 튜닝 (인덱스 스캔 과정에서 발생하는 비효율 줄이기)
- 시력이 1.0~1.5 사이인 모든 ‘김철수’를 찾고 싶을 때, 이름 순서대로 정렬을 해 두었다면 소량만 스캔하면 됨
- 시력 순서대로 정렬 해 두었다면, 스캔 범위가 훨씬 넓어짐
- 랜덤 액세스 최소화 튜닝 (테이블 엑세스 횟수 줄이기)
- 시력이 1.0~1.5 사이인 학생은 총 50명, 이름이 ‘김철수’인 학생은 총 2명이면 이름 순으로 정렬한 데이터가 훨씬 효율적
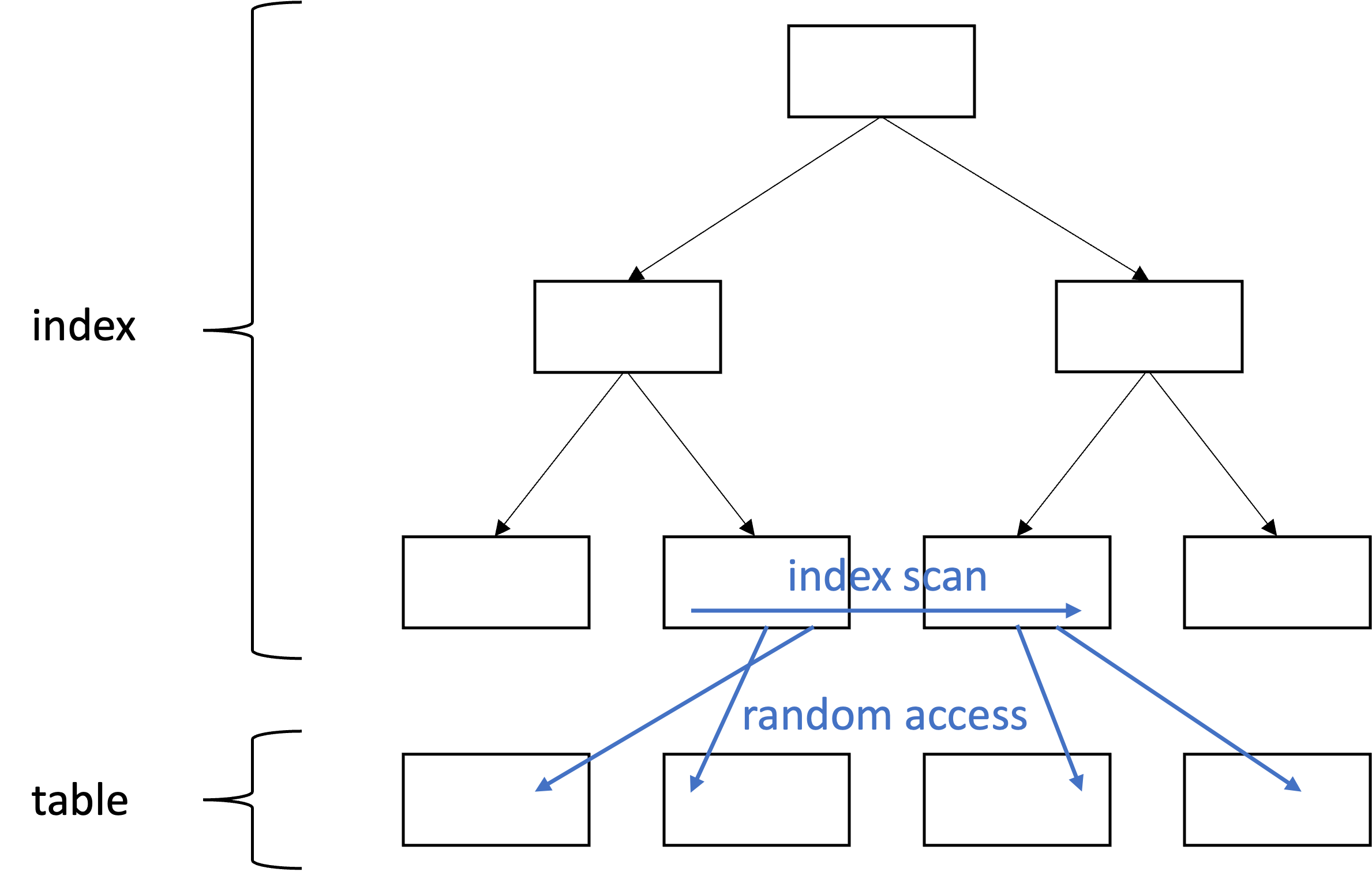
SQL 튜닝의 핵심은 랜덤 I/O를 줄이는 것
- 데이터베이스 성능이 느린 이유는 디스크 I/O
- 인덱스를 많이 사용한다면 디스크 I/O 중에서도 랜덤 I/O가 크리티컬
- sort merge join, hash join, cluster, partition, table prefetch 등 많은 기능들이 랜덤 I/O의 느린 속도를 극복하기 위해 만들어진 것
인덱스 구조
데이터베이스에서 인덱스 없이 데이터를 검색하면 테이블을 전부 다 읽어야 함
인덱스를 이용하면 일부만 읽고 멈출 수 있음. range scan(범위 스캔)이 가능함.
- 범위 스캔이 가능한 이유는 정렬이 되어 있기 때문
DBMS는 일반적으로 B*Tree 인덱스를 사용
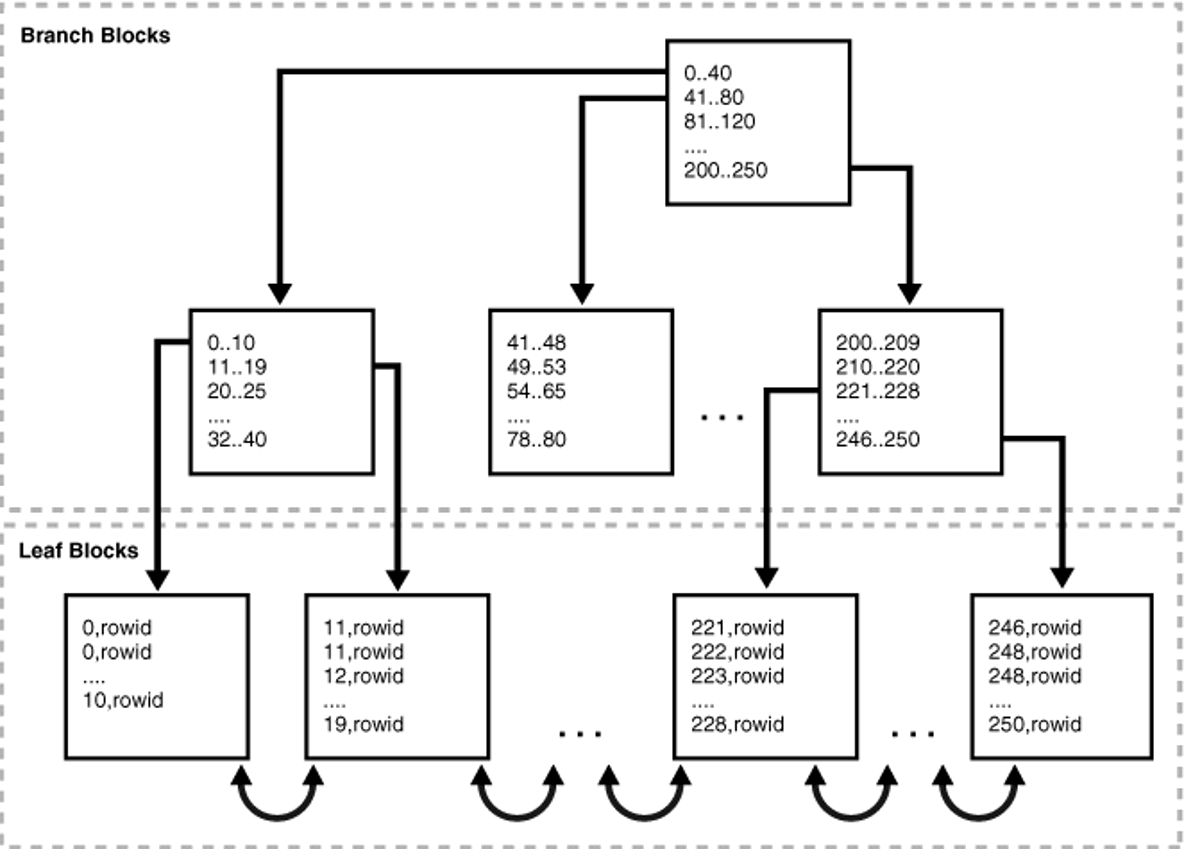
- 루트와 브랜치 블록에 있는 각 레코드는 하위 블록에 대한 주소값을 가짐
키값은 하위 블록에 저장된 키값의 범위를 나타냄. 두 번째 레코드의 키값이 11일 때, 해당 레코드가 가리키는 하위 블록에는 11보다 같거나 큰 레코드가 저장돼 있음.
자식 노드 중 가장 왼쪽에 위치한 블록 (LMC, Leftmost Child)에는 키값을 갖지 않는 레코드가 있음. 키값을 가진 첫 번째 레코드보다 작거나 같은 레코드가 저장돼 있음.
- 리프 블록에 저장된 각 레코드는 키값 순으로 정렬되어 있으며, 테이블 레코드를 가리키는 ROWID를 가짐. 인덱스 키값이 같으면 ROWID 순서로 정렬됨.
- ROWID: 데이터 블록 주소 + 로우 번호
- 데이터 블록 주소: 데이터 파일 번호 + 블록 번호
- 블록 번호: 데이터파일 내에서 부여한 상대적 순번
- 로우 번호: 블록 내 순번
인덱스 탐색 과정은 수직적 탐색과 수평적 탐색으로 나뉨
수직적 탐색
일단 정렬된 인덱스 레코드 중 조건을 만족하는 첫 번째 레코드를 찾아야 함.
인덱스 스캔 시작지점을 찾는 과정.
루트를 포함해 브랜치 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 가짐. 루트에서 시작해 리프 블록까지 수직적 탐색.
- 루트 블록에서 시작
- 찾고자 하는 값보다 크거나 같은 값을 만나면 바로 직전 레코드가 가리키는 하위 블록으로 이동
- 11-19, 20-25 저장되어 있을 때, 13을 찾고 싶다
- 키가 20인 레코드를 만나면, 바로 직전 레코드가 가리키는 하위 블록으로 이동
- 리프 블록에 도달했으면 조건을 만족하는 첫 번째 레코드를 찾아
수직적 탐색은 ‘조건을 만족하는 첫 번째 레코드’를 찾는 게 목표.
index range scan은 이름 그대로 range(범위)를 스캔함. 스캔할 범위의 시작점을 찾는 것.
수평적 탐색
수평적 탐색은 데이터를 찾는 과정.
수직적 탐색을 통해 스캔 시작점을 찾았으면, 찾고자 하는 데이터가 더 안 나타날 때까지 인덱스 리프 블록을 수평적으로 스캔.
- 인덱스 리프 블록끼리는 앞뒤로 double linked list
인덱스를 수평적으로 탐색하는 이유
- 조건절을 만족하는 데이터를 모두 찾기 위해서
- ROWID를 얻기 위해서
- 필요한 칼럼을 인덱스가 모두 갖고 있어 인덱스만 스캔하고 끝나는 경우도 있지만, 일반적으로 인덱스를 스캔하고 나서 테이블도 엑세스 함
- 인덱스가 {이름, 시력}에 대해서 정렬되어 있는데, 사용자가 {키}도 select하면 결국 테이블 가서 읽어와야 함
결합 인덱스 탐색
결합 인덱스 : 두 개 이상 칼럼을 결합해서 인덱스를 생성
[이름, 키] 로 인덱스를 생성하면, 정렬된 순서를 기준으로 키가 생성돼서 하위 블록을 찾아감
[이름, 키] 기준으로 인덱스를 생성하든, [키, 이름] 기준으로 인덱스를 생성하든, 어차피 레코드 개수는 정해져 있고, 정렬된 기준으로 키값 할당돼서 브랜치 블록에 나타나기 때문에 tree height는 동일함.
인덱스 선두 칼럼을 모두 ‘=’ 조건으로 검색할 때는 어느 칼럼을 인덱스 앞쪽에 두든 블록 I/O 개수가 같다. 원하는 레코드를 만날 때까지 타고 내려가는 블록 개수가 같음.
인덱스 기본 사용법
책 제목, 작가, 출판사 가 저장되어 있는 테이블이 있다고 하자. 책 제목 순서대로 정렬이 되어 있다면 ‘수’로 시작하는 책 제목들을 읽으려면 처음 ‘수’를 만난 순간부터 ‘수’로 시작하지 않는 레코드를 만나기 바로 직전 레코드까지 읽으면 된다. 하지만 제목 시작이 아니라 제목 안에 어디든 ‘수’가 들어가 있는 모든 레코드를 읽으려고 하면 결국 테이블 전체를 읽어야 한다.
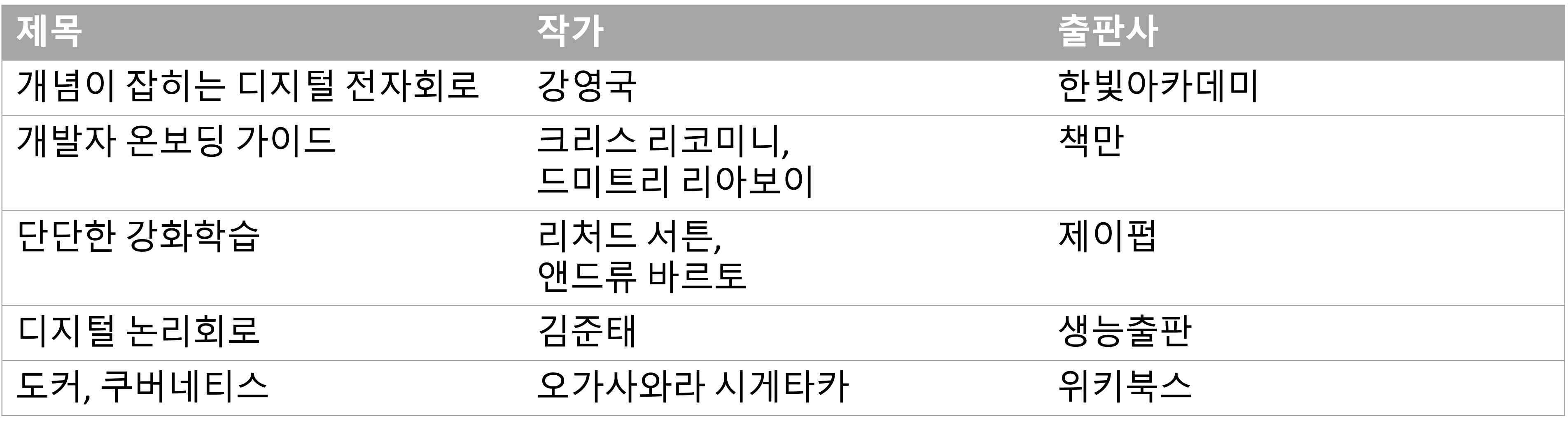
인덱스를 정상적으로 사용한다 = 리프 블록 일부만 스캔하는 index range scan 을 한다
범위를 스캔한다 = 시작과 끝이 있다
- 생일이 2002년 3월 - 2002년 4월 사이에 태어난 사람 찾기 : 범위가 명확
- 인덱스에는 가공되지 않은 값이 저장돼 있는데, 가공된 값을 기준으로 검색하면 시작과 끝을 찾을 수 없음
- 생일이 5월인 사람 찾기 : 인덱스 리프 노드 / 테이블 전부 다 읽어야 함
- where nvl(주문수량, 0) < 10 : null인지 아닌지 확인해야 함
- where name like ‘%진%’ : 중간 값 검색할 때도 다 읽어야 함
- where (전화번호 = ? OR 고객ID = ?) : 시작점 못 찾아
1
2
3
4
5
6
7
8
9
10
11
select *
from customers
where customer_name = :A -- customer_name이 선두 칼럼인 index range scan
union all
select *
from customers
where telephone = :B -- telephone이 선두 칼럼인 index range scan
and (customer_name <> :A or customer_name is null);
select /*+ use_concat */ * from customers
where (telephone = :B or customer_name = :A);
- 각각 인덱스 스캔을 하고 합치는 방법
where telephone in (:B1, :B2) 도 동일하게 UNION ALL 사용하면 브랜치 별로 인덱스 스캔 시작점 찾을 수 있음
1
2
3
4
5
6
7
select *
from customers
where telephone = :B1
union all
select *
from customers
where telephone = :B2
- in 조건정에 대해서는 SQL 옵티마이저가 IN-List Iterator 방식 사용
인덱스 ‘잘’ 타는 조건
인덱스를 [소속팀, 사원명, 연령] 순으로 구성했을 때
1
2
3
select 사원번호, 소속팀, 연령, 입사일자, 전화번호
from 사원
where 사원명 = '홍길동'
과 같이 쿼리를 날리면 결국 리프 노드를 다 읽어야 한다. 소속팀 순서로 먼저 정렬하고, 같은 소속팀 안에서는 사원명 순서로 정렬하는데, 위와 같이 쿼리를 적으면 이름이 ‘홍길동’인 사람이 여러 팀에 흩어지게 된다.
$\therefore$ 인덱스 선두 칼럼이 가공되지 않은 상태로 조건절에 있으면 index range scan 항상 가능
1
2
3
4
5
6
7
8
9
select *
from 주문상품
where 주문일자 = :A
and 상품명 like '%유기농%';
select *
from 주문상품
where 주문일자 = :A
and substr(상품명, 1, 3) = '유기농';
[주문일자, 상품명]으로 인덱스가 구성되어 있으면 인덱스를 타기는 타겠지.
Range scan 하기는 하겠지.
다만, 여기서 ‘상품명’ 칼럼은 가공된 값을 조건으로 사용하고 있어서 범위를 줄이는데 전혀 기여를 안 하고 있다. 해당하는 주문일자의 모든 레코드를 읽게 됨.
인덱스를 사용한 소트 생략
인덱스는 정렬 돼 있다. $\rightarrow$ 잘 하면 소트를 안 해도 된다?
[장비번호, 변경일자, 변경순번]으로 인덱스가 구성되어 있을 때
1
2
3
4
select *
from 상태변경이력
where 장비번호 = 'C'
and 변경일자 = '20180302';
- 위와 같이 장비번호, 변경일자를 모두 ‘=’ 조건으로 검색하면 결과집합은 변경순번 순으로 출력됨
- ‘ORDER BY 변경순번’ 을 쿼리에 붙여도 실행계획에서 sort를 안 함
- ‘ORDER BY 변경순번 Desc’를 사용해도 sort 없이 인덱스 사용 가능. range scan을 위에서 시작해서 아래에서 끝나면 됨.
ORDER BY 절에서 칼럼 가공
1
2
3
4
select *
from 상태변경이력
where 장비번호 = 'C'
order by 변경일자 || 변경순번;
- 가공한 값을 기준으로 정렬해 달라고 하면 정렬 생략 불가능
1
2
3
4
5
6
7
8
9
select *
from (
select TO_CHAR(A.주문번호, 'FM000000') AS 주문번호, A.업체번호, A.주문금액
from 주문 A
where A.주문일자 = ?
and A.주문번호 > NVL(?, 0)
order by 주문번호
)
where ROWNUM <= 30;
- 여기서 order by는 생략되지 않음
- ‘주문번호’는 TO_CHAR로 가공된 값
- ‘order by A.주문번호’로 변경하면 정렬 생략
SELECT-LIST에서 칼럼 가공
1
2
3
4
select MAX(변경순번)
from 상태변경이력
where 장비번호 = 'C'
and 변경일자 = '20180302';
- 수직적 탐색으로 조건을 만족하는 가장 오른쪽 지점 찾고 끝
- MIN 도 마찬가지
1
2
3
4
select NVL(MAX(TO_NUMBER(변경순번)), 0)
from 상태변경이력
where 장비번호 = 'C'
and 변경일자 = '20180302';
- 모든 변경순번을 숫자형으로 바꾸고 나서, 최대를 찾고, null이면 0을 반환
- 정렬 생략 불가
1
2
3
4
select NVL(TO_NUMBER(MAX(변경순번)), 0)
from 상태변경이력
where 장비번호 = 'C'
and 변경일자 = '20180302';
- 이렇게 바꾸면 정렬 생략 가능. 어차피 최대값 찾고 나서 가공
자동 형변환
1
2
select * from customer
where birthday = 20020303;
- birthday 칼럼이 문자열이면 인덱스를 타지 않고 full table scan을 할 수 있음
- 문자열을 숫자로 다 변환하고 있기 때문
- 문자형 < 숫자형
1
2
select * from customer
where signup_date = '01-JAN-2018';
- signup_date가 datetime 형식이면 문자열도 자동 변환됨
- 문자형 < 날짜형
1
2
select max(decode(job, 'PRESIDENT', NULL, sal)) max_sal
from employee;
- decode(a, b, c, d)에서 a = b이면 c를 반환, 아니면 d 반환
- d가 c의 자료형을 따라감
- 오라클에서 decode에 있는 NULL은 자동으로 varchar2로 취급됨
- sal이 문자형으로 잡혀서 결과가 다르게 나올 수 있음
- 원하는 게 있으면 정확히 명시해주자. to_number(NULL)
1
2
3
select * from 거래
where 계좌번호 like :A || '%'
and 거래일자 between :B1 and :B2
- 쿼리를 이렇게 쓰면 계좌번호 :A 자리에 아무것도 안 오면 전체를 검색 가능
- 단, 계좌번호 칼럼이 숫자형이면 like 때문에 문자열로 자동 형변환이 돼서, 계좌번호는 인덱스 조건으로 사용 불가
- [계좌번호, 거래일자] 순으로 인덱스 구성돼 있으면 range scan 불가능
- [거래일자, 계좌번호] 순으로 인덱스 구성돼 있으면 거래일자 만족하는 모든 데이터 읽으면서 계좌번호 다 필터링
인덱스 확장기능 사용법
index full scan
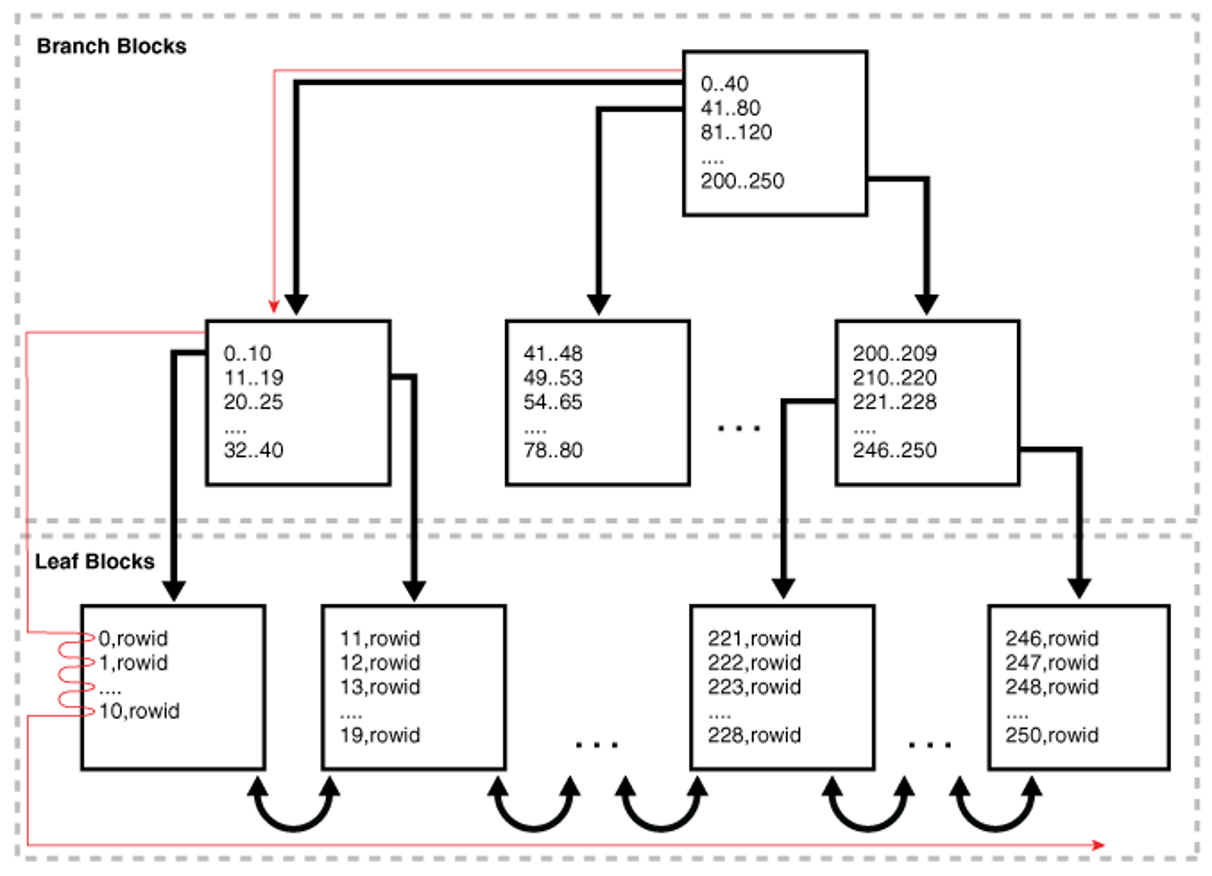
- leaf node 다 읽어
- 만약 찾고자 하는 레코드 개수가 몇 개 없으면 table full scan 대신 index full scan을 한 다음, 찾은 레코드에 대해서 테이블에 가서 다른 칼럼들을 읽는 게 더 효율적일 수도 있음
- 전체를 다 읽더라도 table보다 index가 더 데이터 사이즈가 작으니까 부하가 적음
1
2
3
4
select /*+ first_rows */ *
from employee
where salary > 1000
order by name;
- 읽어야 하는 레코드가 많음에도 불구하고 index full scan 사용
- first rows 힌트 사용 $\rightarrow$ 처음 일부를 빠르게 출력할 목적으로 index full scan
- table full scan보다 더 많은 I/O
index unique scan
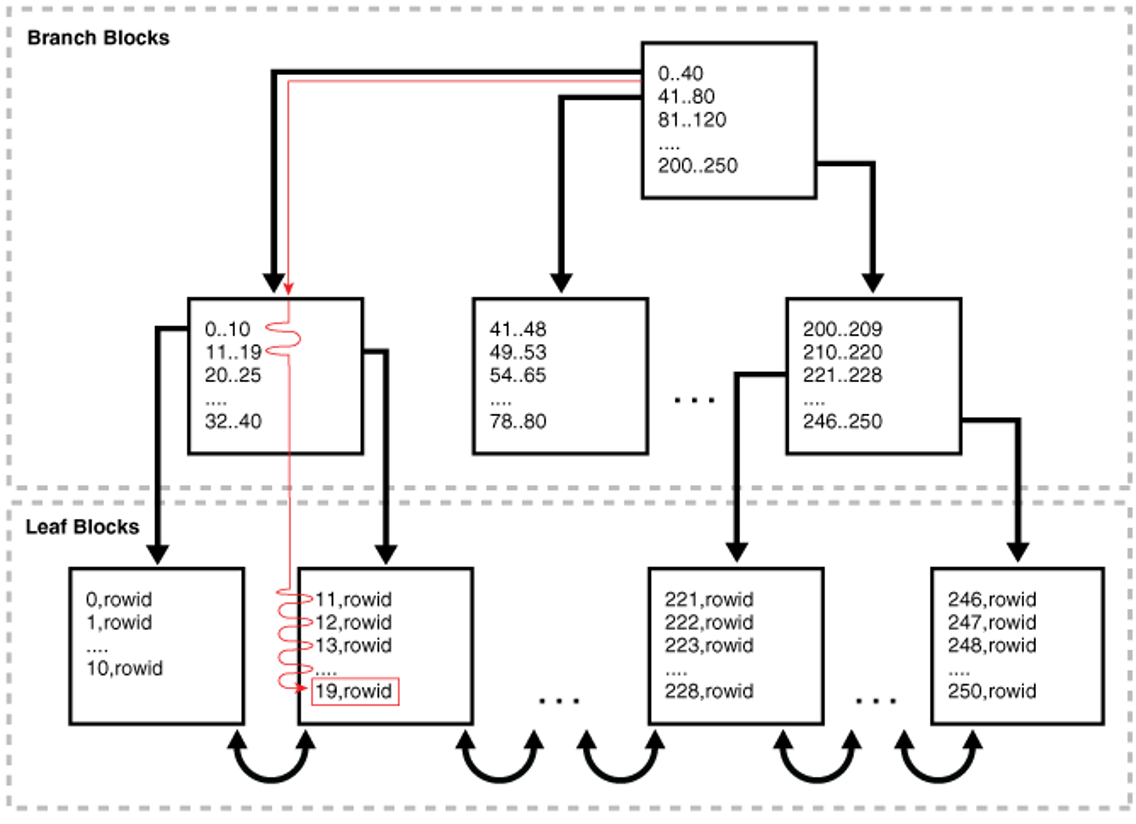
- 수직적 탐색만으로 데이터를 찾음
- unique index를 ‘=’ 조건으로 탐색하는 경우에 작동
1
2
3
4
5
6
create unique index pk_emp on emp(empno);
alter table emp add constraint pk_emp primary key(empno) using index pk_emp;
select empno, ename
from emp
where empno = 5250;
- unique index에 between 같은 범위 검색 조건 사용하면 range scan 처리 됨
index skip scan
- 인덱스 선두 칼럼의 distinct value 개수가 적고, 후행 칼럼의 distinct value 개수가 많을 때 유용함
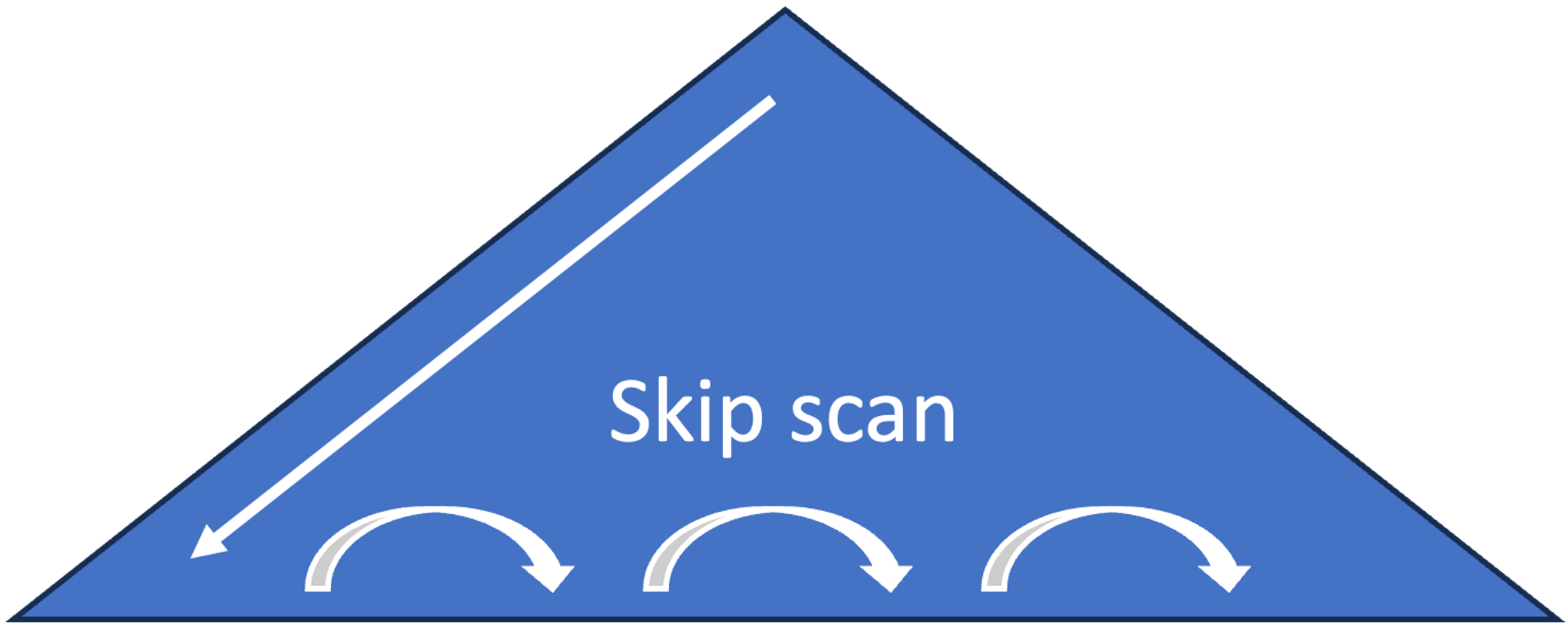
1
SELECT clusterid FROM metrics WHERE tstamp = 100;
[clusterid, tstamp] 순서로 인덱스가 되어 있을 때
- 루트 블록에서 범위 조건에 부합하는 하위 블록만 스캔
- 리프 블록도 정렬이 되어 있을 거잖아. 읽다가 범위 나가면 스탑
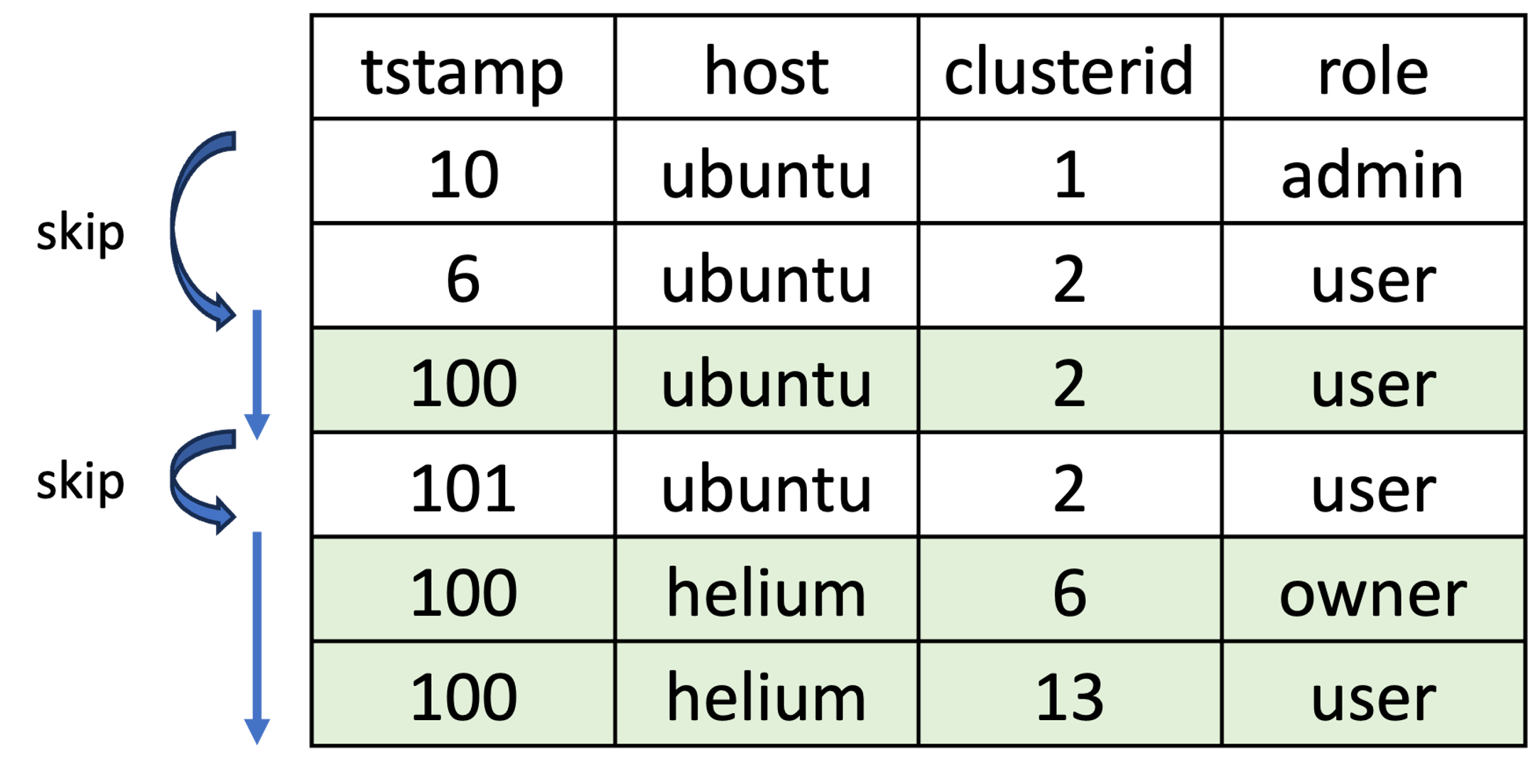
선두 칼럼에 대한 조건절은 있고 중간 칼럼에 대한 조건절이 없는 경우에도 skip scan 사용 가능.
[업종유형코드, 업종코드, 기준일자]로 인덱스가 있을 때
1
2
where 업종유형코드 = '01'
and 기준일자 between '20080501' and '20080531'
- index range scan 사용하면 업종유형코드 = ‘01’인 인덱스 구간 다 읽어야 함
- index skip scan 사용하면 업종유형코드 = ‘01’ 인 블록 중에 기준일자 조건이 맞는 레코드를 포함할 가능성이 있는 리프 블록만 읽음
1
where 기준일자 between '20080501' and '20080531'
선두 칼럼 두 개 다 조건절에 없을 때도 index skip scan 사용 가능
부등호, between, like 같은 범위검색 조건일 때 사용 가능
index fast full scan
논리적인 인덱스 트리 구조 무시하고 인덱스 세그먼트 전체를 Multiblock I/O 방식으로 스캔
논리적 트리
물리적 블록 위치
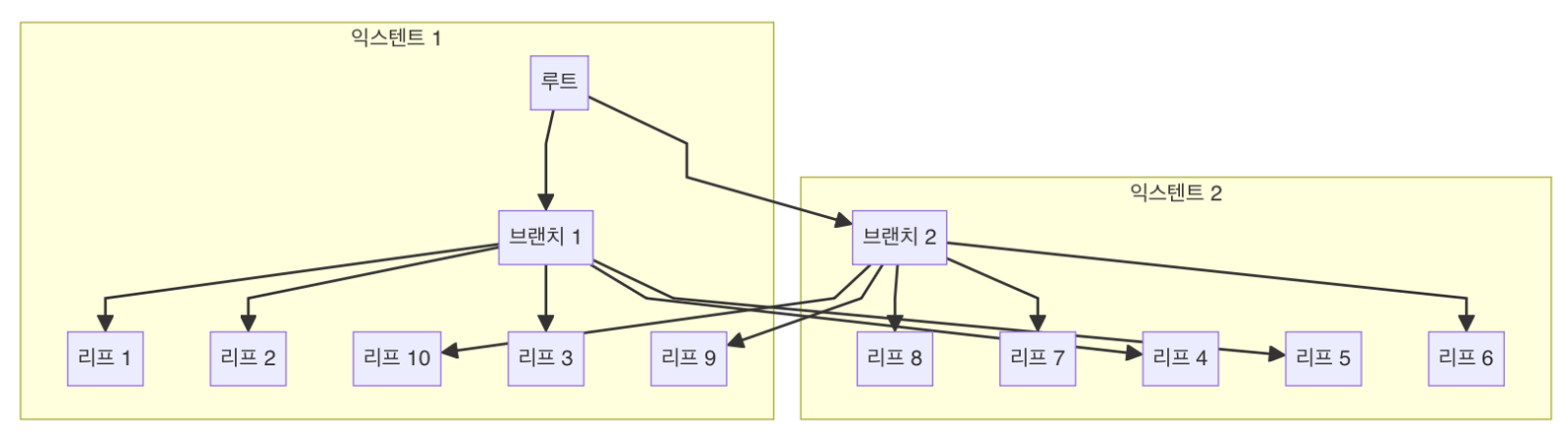
- 디스크로부터 대량의 인덱스 블록을 읽어야 할 때 큰 효과를 발휘
- 인덱스 리프 노드가 갖는 연결 리스트 구조를 무시한 채 읽음 $\rightarrow$ 인덱스 키 순서대로 정렬되지 않음
- 쿼리에 사용한 칼럼이 모두 인덱스에 포함돼 있을 때만 사용
- 인덱스가 파티션 되어 있지 않아도 병렬 쿼리가 가능. Direct Path I/O
출처
친절한 SQL 튜닝
https://docs.oracle.com/en/database/oracle/oracle-database/21/tgsql/optimizer-access-paths.html
https://kudu.apache.org/2018/09/26/index-skip-scan-optimization-in-kudu.html